C++ Atomic Ordering - An x86-TSO's Perspective
本文是笔者对 C++ memory model 中 atomic operations 和 memory order 的理解。
Introduction
The memory model means that C++ code now has a standardized library to call regardless of who made the compiler and on what platform it’s running. There’s a standard way to control how different threads talk to the processor’s memory.
https://www.theregister.com/2011/06/11/herb_sutter_next_c_plus_plus
在 C++11 之前,C++ 是没有明确定义 memory model 的,编写正确、可靠、高效的多线程程序是非常困难的,需要考虑不同的编译器的支持,不同处理器的 memory model 和 cache coherence 等。可以说 C++11 标准的一个最重要的特性就是引入了 memory model,使得开发者不再需要关心编写的程序是使用什么编译器编译、运行在何种处理器上,在 C++ abstract machine 层面上为多线程编程提供了标准化的支持,确保多线程程序的正确性和可移植性。
本文主要包括以下内容:
C++ 中提供了哪些 memory_order,使用不同 memory_order 的 atomic load 和 atomic store 分别表达什么语义。
不同 memory_order 的 atomic load 和 atomic store 在 x86 上是通过哪些汇编指令实现的。
从 Intel® 64 and IA-32 Architectures Software Developer’s Manual 来理解为什么这些汇编指令可以用于实现对应的 memory_order 的 atomic load 和 atomic store。
从 x86-TSO memory model 的角度来理解为什么这些汇编指令可以用于实现对应的 memory_order 的 atomic load 和 atomic store。
如何实现一个简易版本的适用于 x86-64 平台的 atomic_load 和 atomic_store。
本文的最后给出了几个 quiz 测验,用于测试和巩固对 atomic operations 和 memory order 的理解。
std::memory_order
std::memory_order 的作用:
std::memory_orderspecifies how memory accesses, including regular, non-atomic memory accesses, are to be ordered around an atomic operation.
这里的 memory accesses 既包括 atomic memory accesses,也包括 non-atomic memory accesses
这里的 ordered around 既包括 compile-time reordering(done by compiler),也包括 run-time reordering(done by processor)
compile-time reordering
本文这里只举个例子简单说明,建议阅读 https://preshing.com/20120625/memory-ordering-at-compile-time/ 深入了解。
在源代码上对 A 的赋值
A = B + 1;在前,对 B 的赋值B = 0;在后,但是在编译生成的汇编中则是对B的赋值movl $0, B(%rip)在前,对 A 的赋值movl %eax, A(%rip)在后,这就是 compile-time reordering。+----------------+------------------------+------------------------+ | int A, B; | # x86-64 gcc 13.2, -O1 | # x86-64 gcc 13.2, -O2 | | | foo(): | foo(): | | void foo() | movl B(%rip), %eax | movl B(%rip), %eax | | { | addl $1, %eax | movl $0, B(%rip) | | A = B + 1; | movl %eax, A(%rip) | addl $1, %eax | | B = 0; | movl $0, B(%rip) | movl %eax, A(%rip) | | } | ret | ret | +----------------+------------------------+------------------------+run-time reordering
本文这里只举个例子简单说明,建议阅读 https://preshing.com/20120515/memory-reordering-caught-in-the-act/ 深入了解。
+----------------+----------------+ | Processor 0 | Processor 1 | +================+================+ | mov [ _x], 1 | mov [ _y], 1 | | mov r1, [ _y] | mov r2, [ _x] | +----------------+----------------+ | Initially x = y = 0 | | r1 = 0 and r2 = 0 is allowed | +---------------------------------+初始时 x 和 y 都是 0, processor 0 和 processor 1 分别执行相应的汇编指令,我们可能很自然地会认为执行结束后只会出现 r1 =1 或 r2 = 1 或者 r1 = r2 = 1 的情况。但是实际上是可能出现 r1 = r2 = 0 的情况的,看起来就好像是 processor 在运行时对汇编指令进行了 reorder 一样,例如一种可能的 reordering 如下:
Processor0 Processor1 mov r1, [_y] mov [_y], 1 mov r2, [_x] mov [_x], 1看起来就像 procesor 0 在运行时将
mov r1, [_y]reorder 到了mov [_x], 1之前一样。在 “Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3” 的 “9.2.3 Examples Illustrating the Memory-Ordering Principles” 有如下内容:
As noted earlier, the examples refer only to software visible behavior. When the succeeding sections make state- ment such as “the two stores are reordered,” the implication is only that “the two stores appear to be reordered from the point of view of software.”
注意这句 “appear to be reordered from the point of view of software”。
C++ 共有 6 种 memory order:
enum class memory_order : /* unspecified */ {
relaxed, consume, acquire, release, acq_rel, seq_cst
};
inline constexpr auto memory_order_relaxed = memory_order::relaxed;
inline constexpr auto memory_order_consume = memory_order::consume;
inline constexpr auto memory_order_acquire = memory_order::acquire;
inline constexpr auto memory_order_release = memory_order::release;
inline constexpr auto memory_order_acq_rel = memory_order::acq_rel;
inline constexpr auto memory_order_seq_cst = memory_order::seq_cst;
这 6 种 memory order 之间的关系如下图所示:
relaxed-->release--------------->acq_rel-->seq_cst
\-->consume-->acquire--/
x->y means y is stricter/stronger than x
注:当前 C++ 标准明确不鼓励使用 memory_order_consume。并且目前编译器都没有实现 memory_order_consume,只是简单地将 memory_order_consume 转换为 memory_order_acquire。参见:
std::memory_order - cppreference.com “The specification of release-consume ordering is being revised, and the use of memory_order_consume is temporarily discouraged.”
C++ Support in Clang “memory_order_consume is lowered to memory_order_acquire”
LLVM Atomic Instructions and Concurrency Guide — LLVM 19.0.0git documentation “This(Acquire) corresponds to the C++/C memory_order_acquire. It should also be used for C++/C memory_order_consume.
modification order
All modifications to a particular atomic object M occur in some particular total order, called the modification order of M.
[Note 3: There is a separate order for each atomic object. There is no requirement that these can be combined into a single total order for all objects. In general this will be impossible since different threads can observe modifications to different objects in inconsistent orders. — end note]
The following four requirements are guaranteed for all atomic operations:
write-write coherence: If an operation A that modifies an atomic object M happens before an operation B that modifies M, then A is earlier than B in the modification order of M.
read-read coherence: If a value computation A of an atomic object M happens before a value computation B of M, and A takes its value from a side effect X on M, then the value computed by B is either the value stored by X or the value stored by a side effect Y on M, where Y follows X in the modification order of M.
read-write coherence: If a value computation A of an atomic object M happens before an operation B that modifies M, then A takes its value from a side effect X on M, where X precedes B in the modification order of M.
write-read coherence: If a side effect X on an atomic object M happens before a value computation B of M, then the evaluation B takes its value from X or from a side effect Y that follows X in the modification order of M.
relaxed ordering
Atomic operations tagged
memory_order_relaxedare not synchronization operations; they do not impose an order among concurrent memory accesses. They only guarantee atomicity and modification order consistency.
memory_order_relaxed 的 load/store 与普通的 load/store 的唯一区别就是增加了对 load/store 操作的 atomicity 和 modification order consistency 的保证。
atomicity: atomic operations are indivisible. If a thread attempts to atomically read the object that is being modified (also atomically) by another thread, it will either read its value entirely before modification, or entirely after modification, no half-done values.
modification order consistency: all threads can agree on a modification order for that one object. i.e. an order exists.
结合 atomic operations 保证 read/write coherence 和 relaxed atomic operations 保证 modification order consistency 这两个性质,可以得出结论:同一线程内对同一个 object 的 atomic operations 之间不可以进行 reorder。即便两个 atomic operations 是对同一个 object 的 relaxed atomic loads,也不可以对这两个 relaxed atomic loads 进行 reorder。
但是,同一线程内对某个 object 的 relaxed atomic operation 是可以与其他 object 的 memory accesses 进行 reorder 的。
下面通过几个例子来理解 relaxed ordering:
考虑如下代码:
+-----------------------------------------+------------------------------------------+ | Thread 1 | Thread 2 | +=========================================+==========================================+ | r1 = y.load(memory_order_relaxed); // A | r2 = x.load(memory_order_relaxed); // C | | x.store(r1, memory_order_relaxed); // B | y.store(42, memory_order_relaxed); // D | +-----------------------------------------+------------------------------------------+ | std::atomic<int> x{0}, y{0}; | | r1 = r2 = 42 is allowed | +------------------------------------------------------------------------------------+因为 thread 2 中的 C 和 D 是对不同 objects 的 relaxed atomic loads,所以 thread2 中的 D 是允许被 reorder(经 compile-time reordering 或 run-time reordering) 至 C 之前的。当 thread 1 在执行 A 时 thread 2 的 D 对 y 的修改对 thread 1 可能已经是可见的,使得 thread 1 读取到的 y 的值 r1 = 42,然后 thread 1 执行 B 使得 x 的值被修改为 r1 的值 42,之后 thread 2 执行 C 时 thread 1 的 B 对 x 的修改对 thread2 同样可能已经是可见的,所以 thread2 执行 D 读取到的 x 的值就可能为 r2 = 42。因此 r1 = r2 = 42 是可能的。
考虑如下代码:
+----------------------------------------+-----------------------------------------+ | Thread 1 | Thread 2 | +========================================+=========================================+ | x.store(1, memory_order_relaxed); // A | y = x.load(memory_order_relaxed); // C | | x.store(2, memory_order_relaxed); // B | z = x.load(memory_order_relaxed); // D | | | assert (y <= z); // never fires | +----------------------------------------+-----------------------------------------+ | std::atomic<int> x{0}; | +----------------------------------------------------------------------------------+当 y = 1, z = 0 或 y = 2, z = 0 或 y = 2, z = 1 时,
assert(y <= z);会失败。
考虑 y = 2 的情况进行分析:当 thread 2 执行 C 读取到 x 的值是 2 时,说明读取到的是 thread 1 的 B 对 x 修改的值。
根据 read-read coherence,因为 thread 2 的 C 和 D 都是对 x 的 atomic load 并且在源码上 C 是在 D 之前的,所以 thread 2 的 D 读取到的 x 的值要么是 thread 1 中 B 对 x 修改的值,要么是在 x 的 modification order 中位于 B 后面某个操作对 x 修改的值。
根据 write-write coherence,因为 thread 1 的 A 和 B 都是对 x 的 atomic store 并且源码上 A 位于 B 之前,所以在 x 的 modification order 中 A 位于 B 之前。
在本例中,x 的 modification order 就是 A-B ,所以 thread 2 执行 D 读取到的 x 的值一定 2。
考虑 y = 1 的情况进行分析:当 thread 2 执行 C 读取到 x 的值是 1 时,说明读取到的是 thread 1 的 A 对 x 修改的值。
根据 read-read coherence,因为 thread 2 的 C 和 D 都是对 x 的 atomic load 并且在源码上 C 是在 D 之前的,所以 thread 2 的 D 读取到的 x 的值要么是 thread 1 中 A 对 x 修改的值,要么是在 x 的 modification order 中位于 A 后面某个操作对 x 修改的值。
根据 write-write coherence,因为 thread 1 的 A 和 B 都是对 x 的 atomic store 并且源码上 A 位于 B 之前,所以在 x 的 modification order 中 A 位于 B 之前。
在本例中,x 的 modification order 就是 A-B ,所以 thread 2 执行 D 读取到的 x 的值要么是 1 要么是 2。
因此 thread 2 的断言
assert(y <= z);永远不会失败。
release-acquire ordering
memory_order_acquire: A load operation with this memory order performs the acquire operation on the affected memory location: no reads or writes in the current thread can be reordered before this load.
memory_order_release: A store operation with this memory order performs the release operation: no reads or writes in the current thread can be reordered after this store.
memory_order_acquire 和 memory_order_release 是比 memory_order_relaxed 更“强”的 memory order,不仅有与 memory_order_relaxed 一样的 atomicity 和 modification order consistency 的保证,还有如下的保证:
memory_order_acquireatomic load 的 reordering 限制:在源码上位于该 acquire atomic load 之后的 memory accesses 不能被 reorder 至该 acquire atomic load 之前(隐含:在源码上位于该 acquire atomic load 之前的 memory accesses 允许被 reorder 至该 acquire atomic load 之后)。memory_order_releaseatomic store 的 reordering 限制:在源码上位于该 release atomic store 之前的 memory accesses 不能被 reorder 至该 release atomic store 之后(隐含:在源码上位于该 release atomic store 之后的 memory accesses 允许被 reorder 至该 release atomic store 之前)。synchronizes-with 关系:如果 thread A 中的存在一个对 atomic object M 的 release atomic store,thread B 中存在一个对 atomic object M 的 acquire atomic load,如果在运行时 thread B 中的 acquire atomic load 读取到的是 thread A 中 release atomic store 写入的值,那么就称 thread A 中的 release atomic store 与 thread B 中的 acquire atomic load 形成了 synchronizes-with 关系。
如果 thread A 中的 release atomic store 与 thread B 中的 acquire atomic load 形成了 synchronizes-with 关系,那么会保证:thread A 中在源码上位于该 release atomic store 之前的所有 memory writes 都是对 thread B 是可见的,thread B 保证会看到 thread A 中在源码上位于该 release atomic store 之前的操作所写入内存的内容。
只有在程序实际运行时才能确定是否建立了 synchronizes-with 关系,因为 thread B 中的 acquire atomic load 是否读取到的是 thread A 中 release atomic store 存储的值只有在程序实际运行时才能确定。
注意:
对
memory_order_acquire和memory_order_release的 reordering 的限制既包括 compile-time reordering 也包括 run-time reordering。同一线程内对同一个 object 的 atomic operations 之间不可以进行 reorder。
下面通过几个例子来理解 release-acquire ordering:
考虑如下代码:
+------------------------------------------+-----------------------------------------------+ | Thread 1 | Thread 2 | +==========================================+===============================================+ | | std::string* p2; | | auto *p = new std::string("Hello"); // A | while(!(p2 = ptr.load(memory_order_acquire))) | | data = 42; // B | ; | | ptr.store(p, memory_order_release); // C | assert(*p2 == "Hello"); // never fires | | | assert(data == 42); // never fires | +------------------------------------------+-----------------------------------------------+ | int data{0}; | | std::atomic<std::string*> ptr{nullptr}; | +------------------------------------------------------------------------------------------+初始时
std::atomic<std::string*> ptr为 nullptr,如果 thread 2 读取到的std::atomic<std::string*> ptr的值不为 nullptr 说明 thread 2 读取到的std::atomic<std::string*> ptr的值是 thread 1 执行 C 对ptr修改的值,所以此时 thread 1 中的 A 和 B 写入内存的内容一定是对 thread 2 可见的,因此断言assert(*p2 == "Hello")和assert(data == 42)一定不会失败。考虑如下代码:
+--------------------------------------------+-------------------------------------------+ | Thread 1 | Thread 2 | +============================================+===========================================+ | y = 0; | while(a.load(memory_order_acquire) != 10) | | x = 0; | ; | | a.store(10, memory_order_release); | assert(x == 0); // never fires | | y = 1; | r1 = x; | | while(b.load(memory_order_acquire) != 20)) | b.store(20, memory_order_release); | | ; | while(c.load(emory_order_acquire) != 30) | | x = 1; | ; | | c.store(30, memory_order_release); | assert(y == 1); // never fires | | | r2 = y; | +--------------------------------------------+-------------------------------------------+ | int x, y; | | std::atomic<int> a, b, c; | +----------------------------------------------------------------------------------------+与上例类似,断言
assert(x == 0)和assert(y == 1)一定不会失败。如前文所述,如果某个 atomic store 使用的是
memory_order_release,那么位于该 release atomic store 之前的 memory accesses 不允许被 reorder 至该 release atomic store 之后,但是位于该 release atomic store 之后的 memory accesses 是允许被 reorder 至该 release atomic store 之前的。因此编译器可以将 thread 1 的
y = 1;这一语句 reorder 至a.store (10, std::memory_order_release);语句之前,然后编译器就可以通过 Dead Store Elimination 优化来消除y = 0;这一语句,即优化为如下所示代码:x = 0; y = 1; a.store(10, memory_order_release); while(b.load(memory_order_acquire) != 20)) ; x = 1; c.store(30, memory_order_release);
sequentially-consistent ordering
memory_order_seq_cst: A load operation with this memory order performs an acquire operation, a store performs a release operation, and read-modify-write performs both an acquire operation and a release operation, plus a single total modification order of all atomic operations that are so tagged.single total modification order means that all threads are guaranteed to see the same order of memory operations on atomic variables.
memory_order_seq_cst 是比 memory_order_acquire 和 memory_order_release 更“强”的 memory order。使用 memory_order_seq_cst 的 atomic load 有着与 memory_order_acquire 一样的语义,使用 memory_order_seq_cst 的 atomic store 有着与 memory_order_release 一样的语义,并且所有使用 memory_order_seq_cst 的 operations 之间(包括 atomic load, atomic store 和 atomic_thread_fence)存在 single total modification order。
注:不要混淆 memory_order_seq_cst 保证的 single total modification order 与 memory_order_relaxed 保证的 modification order consistency 。
memory_order_relaxed保证的 modification order consistency 是不同的线程对同一个 object 的 atomic operations 的 modification order。memory_order_seq_cst保证的 single total modification order 则是不同线程对所有memory_order_seq_cst的 atomic operations 之间的 modification order。
下面通过几个例子来理解 sequentially-consistent ordering:
考虑如下代码(
std::atomic<T>::load,std::atomic<T>::store的默认 memory_order 参数就是 memory_order_seq_cst,本例中省略了 memory_order 参数):+----------------+----------------+-------------------+-------------------+ | Thread 1 | Thread 2 | Thread 3 | Thread 4 | +================+================+===================+===================+ | | | while (!x.load()) | while (!y.load()) | | x.store(true); | y.store(true); | ; | ; | | | | if (y.load()) | if (x.load()) | | | | ++z; | ++z; | +----------------+----------------+-------------------+-------------------+ | std::atomic<bool> x{false}, y{false}; | | std::atomic<int> z{0}; | | When the four threads finish their execution, z must not be 0. | +-------------------------------------------------------------------------+初始时 x = y = false, z = 0,当这 4 个 threads 执行结束后,z 值一定不为 0。这是因为
memory_order_seq_cst保证所有memory_order_seq_cst的 atomic operations 之间存在 single total modification order。在本例中,只有 x 和 y 两个 atomic object,正好 4 个 threads 中对 x 和 y 的 atomic operations 使用的都是memory_order_seq_cst,所以本例中只存在两种 single total modification order:X-Y 即在 single total modification order 中对 x 的修改先于对 y 的修改。这样,当 thread 4 读取到的 y 的值为 true 时,此时 thread 4 读取到的 x 的值也一定为 true,因此
++z一定会执行,所以 z 一定不为 0。Y-X 即在 single total modification order 中对 y 的修改先于对 x 的修改。这样,当 thread 3 读取到的 x 的值为 true 时,此时 thread 3 读取到的 y 的值也一定为 true,因此
++z一定会执行,所以 z 一定不为 0。
问题:如果将本例中对 x 和 y 的 load/store 使用的 memory order 修改为
memory_order_acquire/memory_order_release,那么当 4 个 threads 执行结束后,z 的值是否还能保证一定不为 0 ?答案:不能保证,即 z 的值可能为 0。因为 release-acquire ordering 不能保证 single total modification order。对于 thread 3 可能是先观测到 x 先被修改为 true 然后再观测到 y 被修改为 true,当 thread 3 执行
y.load(std::memory_order_seq_cst)时还没观测到 y 被修改为 true,所以 thread 3 的++z不会被执行;对于 thread 4 可能是先观测到 y 先被修改为 true 然后再观测到 x 被修改为 true,当 thread 4 执行x.load(std::memory_order_seq_cst)时还没观测到 x 被修改为 true,所以 thread 4 的++z不会被执行。因此当 4 个 threads 执行结束后,z 的值可能为 0。考虑如下代码:
+--------------------------------------+--------------------------------------+ | Thread 1 | Thread 2 | +======================================+======================================+ | x.store(true, memory_order_release); | y.store(true, memory_order_release); | | if (!y.load(memory_order_seq_cst)) | if (!x.load(memory_order_seq_cst)) | | ++z; | ++z; | +--------------------------------------+--------------------------------------+ | int z{0}; | | std::atomic<bool> x{false}, y{false}; | | When the 2 threads finish their execution, z = 2 is allowed | +-----------------------------------------------------------------------------+因为位于
memory_order_acquireatomic load 之前的 memory accesses 允许被 reorder 至该 acquire atomic load 之后,位于memory_order_releaseatomic store 之后的 memory accesses 允许被 reorder 至该 release atomic store 之前,又因为使用memory_order_seq_cst的 atomic load 有着与memory_order_acquire一样的语义,所以 thread 1 的y.load(std::memory_order_seq_cst)是可以被 reorder 至x.store(true, std::memory_order_release)之前的。同理 thread 2 的x.load(std::memory_order_seq_cst)是可以被 reorder 至y.store(true, memory_order_release)之前的。初始时 x 和 y 的值都为 false,所以可能出现的一种执行情况是,thread 1 读取到的 y 的值为 false,thread 2 读取到的 x 的值为 false,因此 thread 1 和 thread 2 会都会执行
z++,使得 thread 1 和 thread 2 执行结束后 z 的值为 2。问题:如果将本例中
x.store(true, std::memory_order_release)修改为x.store(true, std::memory_order_seq_cst),y.store(true, std::memory_order_release)修改为y.store(true, std::memory_order_seq_cst),那么当 thread 1 和 thread 2 执行结束后,z 的值是否还可能为 2 ?答案:z 的值不可能为 2。
mapping C++ atomic operations to x86
本节首先给出 memory_order_relaxed, memory_order_acquire, memory_order_release, memory_order_seq_cst 的 atomic load/store 在 x86 上分别是使用什么汇编指令实现的,然后根据 “Intel® 64 and IA-32 Architectures Software Developer’s Manual” 的相关内容来理解为什么这些汇编指令可以用于实现对应的 memory_order 的 atomic load/store。
本节使用的例子,可以通过 https://godbolt.org/z/zaa7TzjbT 在线查看。
relaxed ordering
int ld_relaxed(std::atomic<int> &i){
return i.load(std::memory_order_relaxed);
}
void st_relaxed(std::atomic<int> &i) {
i.store(1, std::memory_order_relaxed);
}
ld_relaxed(std::atomic<int>&):
movl (%rdi), %eax
ret
st_relaxed(std::atomic<int>&):
movl $1, (%rdi)
ret
GCC 和 Clang 为 memory_order_relaxed 的 atomic load/store 生成的汇编指令是普通的 MOV 指令。
对于 x86,为什么普通的 MOV 指令就能保证 atomicity 和 modification order consistency 呢?
atomicity
在 “Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3” 的 “9.1.1 Guaranteed Atomic Operations " 有如下内容:
The Intel486 processor (and newer processors since) guarantees that the following basic memory operations will always be carried out atomically:
Reading or writing a byte.
Reading or writing a word aligned on a 16-bit boundary.
Reading or writing a doubleword aligned on a 32-bit boundary.
The Pentium processor (and newer processors since) guarantees that the following additional memory operations will always be carried out atomically:
Reading or writing a quadword aligned on a 64-bit boundary.
16-bit accesses to uncached memory locations that fit within a 32-bit data bus.
The P6 family processors (and newer processors since) guarantee that the following additional memory operation will always be carried out atomically:
- Unaligned 16-, 32-, and 64-bit accesses to cached memory that fit within a cache line.
注:这里 “word” 指的是 two 8-bit bytes,“doubleword” 即 32 bits,“quadword” 即 64 bits。
modification order consistency
在 “Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3” 的 “9.2.2 Memory Ordering in P6 and More Recent Processor Families” 有如下内容:
In a multiple-processor system, the following ordering principles apply:
Writes by a single processor are observed in the same order by all processors.
[…]
显然可以保证 modification order consistency。
release-acquire ordering
int ld_acquire(std::atomic<int> &i){
return i.load(std::memory_order_acquire);
}
void st_release(std::atomic<int> &i) {
i.store(1, std::memory_order_release);
}
ld_acquire(std::atomic<int>&):
movl (%rdi), %eax
ret
st_release(std::atomic<int>&):
movl $1, (%rdi)
ret
GCC 和 Clang 为 memory_order_acquire atomic load 和 memory_order_release atomic store 生成的汇编指令是普通的 MOV 指令。
对于 x86,为什么普通的 MOV 指令就能保证 release-acquire 语义呢?
回顾下 memory_order_acquire, memory_order_release 的语义:
memory_order_acquireatomic load 的 reordering 限制:在源码上位于该 acquire atomic load 之后的 memory accesses 不能被 reorder 至该 acquire atomic load 之前。memory_order_releaseatomic store 的 reordering 限制:在源码上位于该 release atomic store 之前的 memory accesses 不能被 reorder 至该 release atomic store 之后。synchronizes-with 关系:如果 thread A 中的存在一个对 atomic object M 的 release atomic store,thread B 中存在一个对 atomic object M 的 acquire atomic load,如果在运行时 thread B 中的 acquire atomic load 读取到的是 thread A 中 release atomic store 写入的值,那么 thread A 中在源码上位于该 release atomic store 之前的所有 memory writes 都是对 thread B 是可见的,thread B 保证会看到 thread A 中在源码上位于该 release atomic store 之前的操作所写入内存的内容。
在 “Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3” 的 “9.2.2 Memory Ordering in P6 and More Recent Processor Families” 有如下内容:
In a single-processor system for memory regions defined as write-back cacheable, the memory-ordering model respects the following principles:
Reads are not reordered with other reads.
Writes are not reordered with older reads.
Writes to memory are not reordered with other writes [..]
[…]
In a multiple-processor system, the following ordering principles apply:
Individual processors use the same ordering principles as in a single-processor system.
Writes by a single processor are observed in the same order by all processors.
[…]
首先讨论 reordering:
对于
memory_order_acquireatomic load,如果 processor 将 later reads 或 writes reorder 到该 load 之前,那么这就违反了 “Reads are not reordered with other reads” 和 “Writes are not reordered with older reads” 这两条 principles。对于
memory_order_releaseatomic store,如果 processor 将 prior reads 或 writes reorder 到 store 之后,那么这就违反了 “Writes are not reordered with older reads” 和 “Writes to memory are not reordered with other writes” 这两条 principles。
然后讨论 synchronizes-with 关系:
- 根据 “Writes to memory are not reordered with other writes” 这一 principles,可知当 thread A 的一条 write 指令 W 执行结束后,thread A 的在 W 之前的所有其他 writes 也都已经执行过了。又因为 “Writes by a single processor are observed in the same order by all processors”,因此当 thread A 的 W 的写入的值对 thread B 可见时,thread A 的在 W 之前的所有其他 writes 的写入的值对 thread B 也一定是可见的。
因此,x86 普通的 MOV 指令就能保证 release-acquire 语义。
sequentially-consistent ordering
int ld_seq_cst(std::atomic<int> &i){
return i.load(std::memory_order_seq_cst);
}
void st_seq_cst(std::atomic<int> &i) {
i.store(1, std::memory_order_seq_cst);
}
ld_seq_cst(std::atomic<int>&):
movl (%rdi), %eax
ret
st_seq_cst(std::atomic<int>&):
movl $1, %eax
xchgl (%rdi), %eax
ret
GCC 和 Clang 为 memory_order_seq_cst atomic load 生成的汇编指令是普通的 MOV 指令,为 memory_order_release atomic store 生成的汇编指令则是 XCHG 指令。
对于 x86,为什么使用 MOV 指令实现 memory_order_seq_cst atomic load 配合 XCHG 指令实现 memory_order_release atomic store 就能保证 sequentially-consistent 语义呢?
回顾下 memory_order_seq_cst 的语义:
使用
memory_order_seq_cst的 atomic load 有着与memory_order_acquire一样的语义使用
memory_order_seq_cst的 atomic store 有着与memory_order_release一样的语义所有
memory_order_seq_cst的 atomic operations 之间存在 single total modification order
在上一节已经说明了 MOV 指令就能保证 release-acquire 语义。所以问题的关键就是如何保证 single total modification order ?
在 “Intel® 64 and IA-32 Architectures Software Developer’s Manual” 中有如下相关内容:
在 Volume 2 的 “LOCK—Assert LOCK# Signal Prefix” 一节:
Causes the processor’s LOCK# signal to be asserted during execution of the accompanying instruction (turns the instruction into an atomic instruction). In a multiprocessor environment, the LOCK# signal ensures that the processor has exclusive use of any shared memory while the signal is asserted.
在 Volume 3 的 “9.2.3.8 Locked Instructions Have a Total Order” 有如下内容:
The memory-ordering model ensures that all processors agree on a single execution order of all locked instructions, including those that are larger than 8 bytes or are not naturally aligned.
The memory-ordering model prevents loads and stores from being reordered with locked instructions that execute earlier or later.
在 “Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3” 的 “9.1.2.1 Automatic Locking” 有如下内容:
The operations on which the processor automatically follows the LOCK semantics are as follows:
When executing an XCHG instruction that references memory.
[…]
根据上述内容可知:XCHG 指令是隐式的带 LOCK 前缀的指令,有着 LOCK 语义,所有带 LOCK 前缀的指令存在 single execution order。
还是通过一个例子来理解:
+-------------------------------------------+-------------------------------------------+
| Thread 1 | Thread 2 |
+===========================================+===========================================+
| x.store(true, std::memory_order_seq_cst); | y.store(true, std::memory_order_seq_cst); |
| r1 = x.load(std::memory_order_seq_cst); | r3 = y.load(std::memory_order_seq_cst); |
| r2 = y.load(std::memory_order_seq_cst); | r4 = x.load(std::memory_order_seq_cst); |
+-------------------------------------------+-------------------------------------------+
| std::atomic<bool> x{false}, y{false}; |
| r1 = true, r2 = false, r3 = true and r4 = false is not allowed |
+---------------------------------------------------------------------------------------+
如果 r1 = true, r2 = false, r3 = true, r4 = false,说明:
对于 thread 1 来说 x 和 y 的 modification order 是先 x 后 y,当 thread 1 执行
x.load(std::memory_order_seq_cst)时已观测到 x 被修改为 true,当 thread 1 执行y.load(std::memory_order_seq_cst)时还未观测到 y 被修改为 true对于 thread 2 来说 x 和 y 的 modification order 是先 y 后 x,当 thread 2 执行
y.load(std::memory_order_seq_cst)时已观测到 y 被修改为 true,当 thread 2 执行x.load(std::memory_order_seq_cst)时还未观测到 x 被修改为 true
但是实际上 r1 = true, r2 = false, r3 = true, r4 = false 是不可能发生的,memory_order_release atomic store 生成的汇编指令是 XCHG 指令,XCHG 指令是隐式的带 LOCK 前缀的指令,“all processors agree on a single execution order of all locked instructions”,所以 thread 1 和 thread 2 观测到的 x.store(true, std::memory_order_seq_cst); 和 x.store(true, std::memory_order_seq_cst); 的执行顺序是一样的,即 thread 1 和 thread 2 观测到的 x 和 y 的 modification order 是一样的。
基于这个例子应该就对“为什么使用 MOV 指令实现 memory_order_seq_cst atomic load 配合 XCHG 指令实现 memory_order_release atomic store 就能保证 sequentially-consistent 语义”能有一定的理解了。但是可能还是有一些混沌,继续阅读下一节 “x86-TSO programmer’s model” 可以消除这些疑惑和不解。
x86-TSO(Total Store Ordering) programmer’s model
x86-TSO 由 Peter Sewell 在论文 x86-TSO: a rigorous and usable programmer’s model for x86 multiprocessors 中提出。有了 x86-TSO,我们就不再需要对 Intel® 64 and IA-32 Architectures Software Developer’s Manual 做阅读理解,基于 x86-TSO 就可以很容易地 reason about 多线程程序的行为。
需要强调的是:x86-TSO 是一个 programmer’s model,x86-TSO 并不是真实的处理器内部实现。
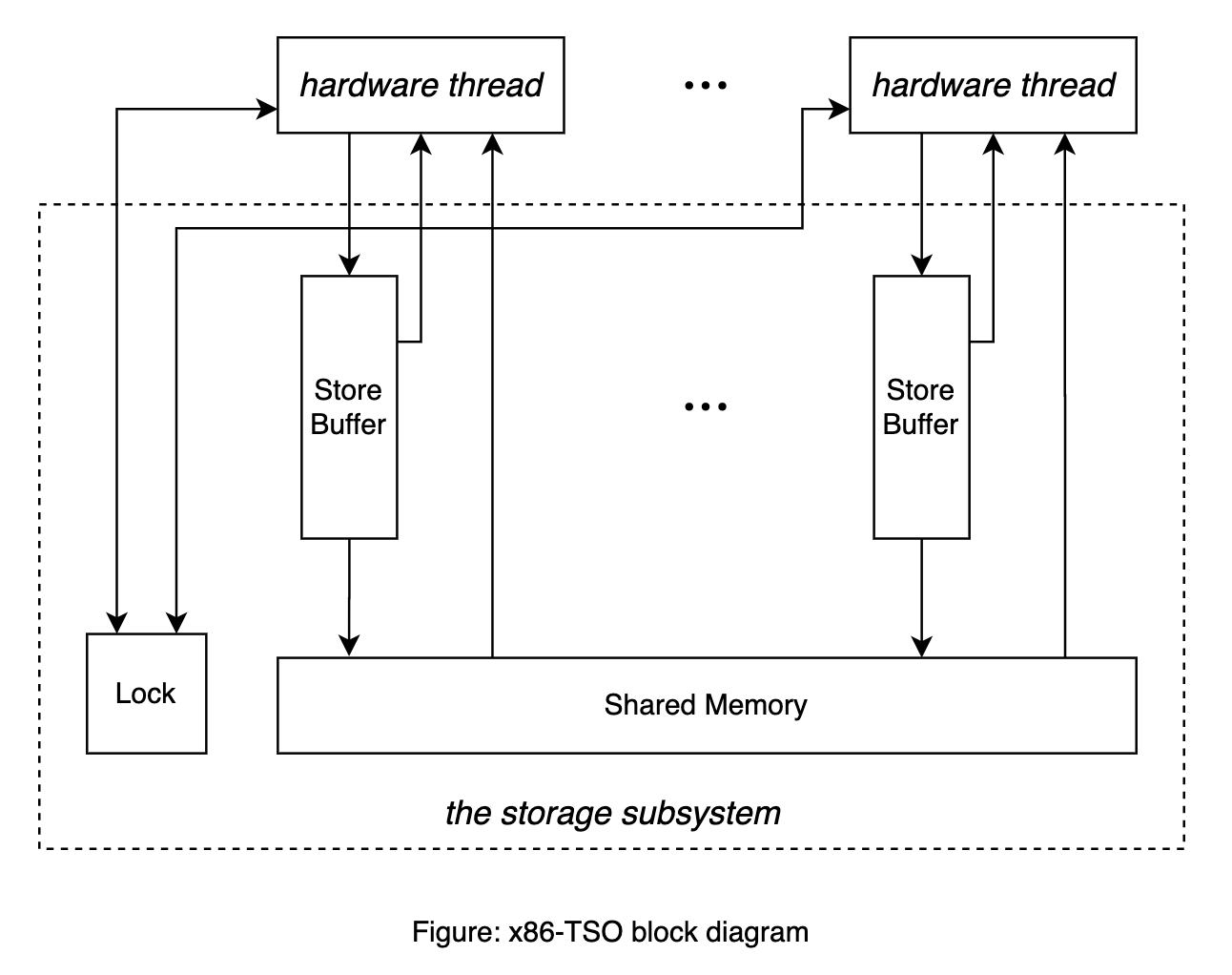
x86-TSO programmer’s model 如上图所示:
有若干 hardware threads,每一个 hardware thread 对应 single in-order stream of instruction execution。
Storage subsystem 是图中通过虚线圈起来的部分:
Shared memory。不解释。
Lock 是一个全局锁。当某个 hardware thread 需要对 shared memory 进行独占访问时,需要持有该 lock。
Store buffer。每一个 hardware thread 都对应一个 FIFO 的 store buffer。
Hardware thread 与 storage subsystem 之间的交互用实线表示:
如果 storage subsystem 的 lock 被某个 hardware thread 持有,那么除该 hardware thread 以外的其他 hardware threads 就是 blocked 状态。
$R_p[a]=v$:如果 hardware thread $p$ 没有被 blocked,那么 hardware thread $p$ 可以读内存地址为 $a$ 处的值,读取到的值记作 $v$。如果 hardware thread $p$ 的 store buffer 中存在对内存地址 $a$ 的写,那么读到的值 $v$ 就是 store buffer 中最新的向内存地址 $a$ 写入的值(称为 store forwarding);如果 hardware thread $p$ 的 store buffer 中不存在对内存地址 $a$ 的写,那么读到的值 $v$ 就是 shared memory 中内存地址 $a$ 保存的值。
$W_p[a]=v$:在任意时刻,不论 hardware thread $p$ 是否被 blocked,hardware thread $p$ 都可以执行向内存地址 $a$ 写入值 $v$ 的写操作,写操作总是先保存在该 hardware thread 的 store buffer 中。
$\tau_p$:如果 hardware thread $p$ 没有被 blocked,它可以默默地将保存在 store buffer 中的写操作生效至 shared memory 中,并且无需与任何其他的 hardware thread 协调。
$F_p$:Hardware thread $p$ 执行 MFENCE 指令会 flush 该 hardware thread $p$ 的 store buffer,即执行多次 $\tau_p$ 操作将保存在 store buffer 中的写操作生效至 shared memory,直至 store buffer 为空。
$L_p$:Hardware thread $p$ 执行带 LOCK 前缀的指令,首先会申请 storage subsystem 的 lock,然后执行指令,在指令执行结束后会 flush store buffer,最后释放 storage subsystem 的 lock。 注意:当某个 hardware thread 持有 storage subsystem 的 lock 时,其他 hardware threads 是 blocked,无法执行读操作。
litmus tests
在 “Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3” 的 “9.2 MEMORY ORDERING” 这一节和 “AMD64 Architecture Programmer’s Manual, Volume 2” 的 “7.2 Multiprocessor Memory Access Ordering” 这一节中,给出了一些示例来帮助理解 memory ordering,这些示例称为 litmus tests。
litmus tests 中使用的符号约定如下:
Processor 指的是 logical processor。x86-TSO 中的 hardware thread 与之对应。
汇编指令中的 r1, r2, etc 表示仅对当前 processor 可见的寄存器。
Shared memory 中的 memory location 用 x, y, z 表示,x, y, z 的内存地址分别用 _x, _y, _z 表示。
汇编指令
mov [ _x], val表示将值 val 写入到 memory location x 中。汇编指令
mov r, [ _x]表示将 memory location x 中存储的值读取到寄存器 r 中。
本节接下来从 x86-TSO 的角度解读这些 litmus tests:
Intel Example 9-1. Stores Are Not Reordered with Other Stores
+-----------------+-----------------+ | Processor 0 | Processor 1 | +=================+=================+ | mov [ _x], 1 | mov r1, [ _y] | | mov [ _y], 1 | mov r2, [ _x] | +-----------------+-----------------+ | Initially x = y = 0 | | r1 = 1 and r2 = 0 is not allowed | +-----------------------------------+根据 x86-TSO,processor 0 将值 1 写入到 memory location x, y 处的写操作总是先保存至其 FIFO 的 store buffer,然后再由 store buffer 生效至 shared memory 中,又因为 processor 1 的 store buffer 中没有对 memory location x, y 的写操作,所以 processor 1 是从 shared memory 中读取 memory location x, y 的值。如果 processor 1 从 shared memory 中读取到的 memory location y 的值 r1 = 1,那么说明 processor 0 的
mov [ _y], 1已经生效至 shared memory 了,而 store buffer 是 FIFO 的,所以 processor 0 的mov [ _x], 1也一定已经执行并生效至 shared memory 了,那么 processor 1 从 shared memory 中读取到 memory location x 的值 r2 一定是 1,所以不可能出现 r1 = 1 且 r2 = 0 的情况。Intel Example 9-2. Stores Are Not Reordered with Older Loads
+-----------------+-----------------+ | Processor 0 | Processor 1 | +=================+=================+ | mov r1, [ _x] | mov r2, [ _y] | | mov [ _y], 1 | mov [ _x], 1 | +-----------------+-----------------+ | Initially x = y = 0 | | r1 = 1 and r2 = 1 is not allowed | +-----------------------------------+如果 processor 0 从 shared memory 中读取到的 memory location x 的值 r1 = 1,那么说明 processor 1 的
mov [ _x], 1已经执行并生效至 shared memory 了,所以 processor 1 的mov r2, [ _y]也一定已经执行过了,而初始时 x = y = 0,因此 processor 1 执行mov r2, [ _y]从 shared memory 中读取到 memory location y 的值 r2 一定是 0,所以不可能出现 r1 = 1 且 r2 = 1 的情况。Intel Example 9-3. Loads May be Reordered with Older Stores
+----------------+----------------+ | Processor 0 | Processor 1 | +================+================+ | mov [ _x], 1 | mov [ _y], 1 | | mov r1, [ _y] | mov r2, [ _x] | +----------------+----------------+ | Initially x = y = 0 | | r1 = 0 and r2 = 0 is allowed | +---------------------------------+存在可能,当 processor 0 执行
mov r1, [ _y]时,processor 1 的mov [ _y], 1写操作还在 processor 1 的 store buffer 中,没有生效至 shared memory,processor 0 执行mov r1, [ _y]读取到的 memory location y 的值 r1 还是 y 的初始值 0;存在可能,当 processor 1 执行mov r2, [ _x]时,processor 0 的mov [ _x], 1写操作还在 processor 0 的 store buffer 中,没有生效至 shared memory,processor 1 执行mov r2, [ _x]读取到的 memory location x 的值 r2 还是 x 的初始值 0。所以可能出现 r1 = 0 且 r2 = 0 的情况。Intel Example 9-4. Loads Are not Reordered with Older Stores to the Same Location
+-----------------------+ | Processor 0 | +=======================+ | mov [ _x], 1 | | mov r1, [ _x] | +-----------------------+ | Initially x = 0 | | r1 = 0 is not allowed | +-----------------------+根据 x86-TSO,processor 0 在执行
mov r1, [ _x]读取 memory location x 的值时,如果其的 store buffer 中存在对 memory location x 的写操作,那么读到的值就是 store buffer 中最新的向 memory location x 写入的值,如果 processor 0 的 store buffer 中不存在对 memory location x 的写,那么读到的值就是 shared memory 中 memory location x 的值。因此 processor 0 执行mov r1, [ _x]读取到的 memory location x 的值 r1 一定是 1,不可能出现 r1 = 0 的情况。Intel Example 9-5. Intra-Processor Forwarding is Allowed
+----------------+----------------+ | Processor 0 | Processor 1 | +================+================+ | mov [ _x], 1 | mov [ _y], 1 | | mov r1, [ _x] | mov r3, [ _y] | | mov r2, [ _y] | mov r4, [ _x] | +----------------+----------------+ | Initially x = y = 0 | | r2 = 0 and r4 = 0 is allowed | +---------------------------------+该例子与 “Intel Example 9-3. Loads May be Reordered with Older Stores” 类似,不再赘述。
Intel Example 9-6. Stores Are Transitively Visible
+---------------+----------------+----------------+ | Processor 0 | Processor 1 | Processor 2 | +===============+================+================+ | mov [ _x], 1 | mov r1, [ _x] | mov r2, [ _y] | | | mov [ _y], 1 | mov r3, [_x] | +---------------+----------------+----------------+ | Initially x = y = 0 | | r1 = 1, r2 = 1, r3 = 0 is not allowed | +-------------------------------------------------+假设 r2 = 1, r1 = 1,即 processor 2 执行
mov r2, [ _y]读取到的 memory location y 的值 r2 = 1,processor 1 执行mov r1, [ _x]读取到的 memory location x 的值 r1 = 1。如果 processor 2 执行mov r2, [ _y]读取到的 memory location y 的值 r2 = 1,说明 processor 1 的mov [ _y], 1已经执行且生效至 shared memory,所以 processor 1 的mov r1, [ _x]已经一定执行过了。processor 1 执行mov r1, [ _x]读取到的 memory location x 的值 r1 = 1,说明 processor 0 的mov [ _x], 1也已经执行且生效至 shared memory 了。因此 processor 2 执行mov r3, [_x]读取到的 memory location x 的值 r3 一定为 1,不可能出现 r1 = 1, r2 = 1, r3 = 0 的情况。Intel Example 9-7. Stores Are Seen in a Consistent Order by Other Processors
+---------------+---------------+----------------+----------------+ | Processor 0 | Processor 1 | Processor 2 | Processor 3 | +===============+===============+================+================+ | mov [ _x], 1 | mov [ _y], 1 | mov r1, [ _x] | mov r3, [ _y] | | | | mov r2, [ _y] | mov r4, [ _x] | +---------------+---------------+----------------+----------------+ | Initially x = y =0 | | r1 = 1, r2 = 0, r3 = 1, r4 = 0 is not allowed | +-----------------------------------------------------------------+假设 r1 = 1, r3 = 1,即 processor 2 执行
mov r1, [ _x]读取到的 memory location x 的值 r1 = 1,processor 3 执行mov r3, [ _y]读取到的 memory location y 的值 r3 = 1。如果 processor 2 执行mov r1, [ _x]读取到的 memory location x 的值 r1 = 1,说明 processor 0 的mov [ _x], 1已经执行且生效至 shared memory,processor 3 执行mov r3, [ _y]读取到的 memory location y 的值 r1 = 1,说明 processor 1 的mov [ _y], 1也已经执行且生效至 shared memory 了。因此 processor 2 执行mov r2, [ _y]读取到的 memory location y 的值 r2 一定为 1,processor 3 执行mov r4, [ _x]读取到的 memory location x 的值 r4 一定为 1,所以不可能出现 r1 = 1, r2 = 0, r3 = 1, r4 = 0 的情况。Intel Example 9-8. Locked Instructions Have a Total Order
+-----------------+-----------------+----------------+---------------+ | Processor 0 | Processor 1 | Processor 2 | Processor 3 | +=================+=================+================+===============+ | xchg [ _x], r1 | xchg [ _y], r2 | mov r3, [ _x] | mov r5, [_y] | | | | mov r4, [ _y] | mov r6, [_x] | +-----------------+-----------------+----------------+---------------+ | Initially r1 = r2 = 1, x = y = 0 | | r3 = 1, r4 = 0, r5 = 1, r6 = 0 is not allowed | +--------------------------------------------------------------------+该例子与 “Intel Example 9-7. Stores Are Seen in a Consistent Order by Other Processors” 类似。
假设 r3 = 1, r5 = 1,即 processor 2 执行
mov r3, [ _x]读取到的 memory location x 的值 r3 = 1,processor 3 执行mov r5, [ _y]读取到的 memory location y 的值 r5 = 1。如果 processor 2 执行mov r3, [ _x]读取到的 memory location x 的值 r3 = 1,说明 processor 0 的xchg [ _x], r1指令已经执行了,因为xchg指令是一个隐式的带 LOCK 前缀的指令,执行结束后会 flush store buffer,因此xchg [ _x], r1执行结束后一定会生效至 shared memory。如果 processor 3 执行mov r5, [ _y]读取到的 memory location y 的值 r5 = 1,说明 processor 1 的xchg [ _y], r2指令也已经执行且生效至 shared memory 了。因此 processor 2 执行mov r4, [ _y]读取到的 memory location y 的值 r4 一定为 1,processor 3 执行mov r6, [ _x]读取到的 memory location x 的值 r6 一定为 1,所以不可能出现 r3 = 1, r4 = 0, r5 = 1, r6 = 0 的情况。Intel Example 9-9. Loads Are not Reordered with Locks
+-----------------+-----------------+ | Processor 0 | Processor 1 | +=================+=================+ | xchg [ _x], r1 | xchg [ _y], r3 | | mov r2, [ _y] | mov r4, [ _x] | +-----------------+-----------------+ | Initially x = y = 0, r1 = r3 = 1 | | r2 = 0 and r4 = 0 is not allowed | +-----------------------------------+假设 r2 = 0 即 processor 0 执行
mov r2, [ _y]读取到的 memory location y 的值 r2 = 0,因为xchg指令是隐式的带 LOCK 前缀的指令,执行结束后会 flush store buffer,所以说明此时 processor 1 还未执行xchg [ _y], r3。此时 processor 1 依次执行xchg [ _y], r3,mov r4, [ _x],执行mov r4, [ _x]读取到的 memory location x 的值 r4 一定为 1,因为 processor 0 此时已经执行完xchg [ _x], r1,将 memory location x 的值修改为 1 已经生效至 shared memory 了。因此不可能出现 r2 = 0, r4 = 0 的情况。Intel Example 9-10. Stores Are not Reordered with Locks
+------------------+-----------------+ | Processor 0 | Processor 1 | +==================+=================+ | xchg [ _x], r1 | mov r2, [ _y] | | mov [ _y], 1 | mov r3, [ _x] | +------------------+-----------------+ | Initially x = y = 0, r1 = 1 | | r2 = 1 and r3 = 0 is not allowed | +------------------------------------+如果 processor 1 执行
mov r2, [ _y]读取到的 memory location y 的值 r2 = 1,说明 processor 0 的mov [ _y], 1已经执行了,所以 processor 0 一定已经执行过了xchg [ _x], r1,因为xchg指令是带 LOCK 前缀的指令,执行结束后会 flush store buffer,所以对 memory location x 的修改一定生效至 shared memory 了。因此 processor 1 执行mov r3, [ _x]读取到的 memory location x 的值 r3 一定为 1,不可能出现 r2 = 1, r3 = 0 的情况。AMD Example 7-5
+----------------+-----------------+ | Processor 0 | Processor 1 | +================+=================+ | mov [ _x], 1 | mov [ _y], 1 | | mfence | mfence | | mov r1, [ _y] | mov r2, [ _x] | +----------------+-----------------+ | Initially x = y = 0 | | r1 = 0 and r2 = 0 is not allowed | +----------------------------------+该例子与 “Intel Example 9-9. Loads Are not Reordered with Locks” 类似,在 “Intel Example 9-9. Loads Are not Reordered with Locks” 是
xchg指令执行结束后会 flush store buffer,本例中则是执行mfence指令来 flush store buffer。假设 r1 = 0 即 processor 0 执行
mov r1, [ _y]读取到的 memory location y 的值 r1 = 0,说明此时 processor 1 还未执行mfence,此时 processor 1 依次执行mfence,mov r2, [ _x],执行mov r2, [ _x]读取到的 memory location x 的值 r2 一定为 1,因为 processor 0 此时已经执行完mov [ _x], r1,mfence,将 memory location x 的值修改为 1 已经生效至 shared memory 了。因此不可能出现 r1 = 0, r2 = 0 的情况。AMD Example 7-9
+------------------------+-------------------------+ | Processor 0 | Processor 1 | +========================+=========================+ | mov [ _x], 1 | mov [ _y], 1 | | mfence | mfence | | mov r1, [ _x] | mov r3, [ _y] | | mov r2, [ _y] | mov r4, [ _x] | +------------------------+-------------------------+ | Initially x = y = 0 | | r1 = 1, r2 = 0, r3 = 1 and r4 = 0 is not allowed | +--------------------------------------------------+假设 r1 = 1, r2 = 0,这说明 processor 0 执行
mov r2, [ _y]时,processor 1 还未执行mfence。在 processor 0 执行完mov r2, [ _y]后,processor 1 依次执行mfence,mov r3, [ _y],mov r4, [ _x],此时 r3 的值一定为 1,因为此时 processor 1 已经执行完mov [ _y], 1,mfence将 memory location y 的值修改为 1 并生效至 shared memory,r4 的值也一定为 1,因为此时 processor 0 已经执行完mov [ _x], 1,mfence将 memory location x 的值修改为 1 并生效至 shared memory 了。因此,不可能出现 r1 = 1, r2 = 0, r3 = 1, r4 = 0 的情况。
conclusion
一句话总结 x86-TSO 就是 sequentially-consistent ordering + a store buffer with store forwarding。
所以在 x86 上实现 sequentially-consistent ordering 只需要避免 store forwarding,因此有以下几种实现:
memory_order_seq_cstatomic load 用 MOV 实现,memory_order_seq_cstatomic store 用 XCHG 实现memory_order_seq_cstatomic load 用 MOV 实现,memory_order_seq_cstatomic store 用 MOV + MFENCE 实现memory_order_seq_cstatomic load 用 LOCK XADD(0) 实现,memory_order_seq_cstatomic store 用 MOV 实现memory_order_seq_cstatomic load 用 MFENCE + MOV 实现,memory_order_seq_cstatomic store 用 MOV 实现
因为通常情况下程序中的 load 比 store 多,所以编译器选择的是前两种实现方案。目前 GCC 13.2 和 Clang 18.1.0 选择的都是方案 1,一些老版本的 GCC 如 8.3 则选择的是方案 2。
感兴趣可以阅读 llvm/lib/Target/X86/X86ISelLowering.cpp 的代码,LowerATOMIC_STORE() 函数实现了将 atomic store 转换为对应的 x86 汇编指令。
memory barrier
前面提到,reordering 包括 compile-time reordering 和 run-time reordering,memory barrier 的作用就是限制编译器和处理器进行相应的 reordering,所以 memory barrier 可以分为 compile-time barrier 和 run-time barrier。
注意,run-time barrier 也会起到 compile-time barrier 的作用, 限制编译器进行 reordering。
在 C++11 引入 memory model 之前,常见的 compile-time barrier 是 asm volatile ("" ::: "memory"),常见的 run-time barrier 则是 GCC 提供的 built-in function __sync_synchronize()。
asm volatile ("" ::: "memory")No reads or writes can reorder (at compile time) with the barrier in either direction, therefore no operation before the barrier can reorder with any operation after the barrier, or vice versa.
Why can asm volatile(”” ::: “memory”) serve as a compiler barrier?
__sync_synchronize()This built-in function issues a full memory barrier.
That is, no memory operand is moved across the operation, either forward or backward. Further, instructions are issued as necessary to prevent the processor from speculating loads across the operation and from queuing stores after the operation.
https://gcc.gnu.org/onlinedocs/gcc/_005f_005fsync-Builtins.html
在 C++11 中引入了 std::atomic_signal_fence 和 std::atomic_thread_fence,atomic_signal_fence 是 compile-time barrier,atomic_thread_fence 是 run-time barrier。
void atomic_signal_fence(std::memory_order order)常见用法是
atomic_signal_fence(memory_order_acq_rel)和atomic_signal_fence(memory_order_seq_cst),效果与asm volatile ("" ::: "memory")相同。void atomic_thread_fence(std::memory_order order)atomic_signal_fence(memory_order_relaxed)无意义。atomic_thread_fence(memory_order_acquire)和atomic_thread_fence(memory_order_consume)称为 acquire fence。An acquire fence prevents the memory reordering of any read which precedes it in program order with any read or write which follows it in program order.
acquire fence 限制:源码上位于该 acquire fence 之前的任意 load/read 都不能与源码上位于该 acquire fence 后的 memory accesses 进行 reordering。
atomic_thread_fence(memory_order_release)称为 release fence。A release fence prevents the memory reordering of any read or write which precedes it in program order with any write which follows it in program order.
release fence 限制:源码上位于该 release fence 前的 memory accesses 都不能与源码上位于该 release fence 后的任意 store/write 进行 reordering。
atomic_thread_fence(memory_order_acq_rel),既是 acquire fence 也是 release fence。atomic_thread_fence(memory_order_seq_cst),既是 acquire fence 也是 release fence,还保证所有使用memory_order_seq_cst的 operations 之间(包括 atomic load, atomic store 和 atomic_thread_fence)存在 single total modification order。
注意,
atomic_thread_fence对 reordering 的限制要比使用相同 std::memory_order 的 atomic load/store 更强(建议阅读 https://preshing.com/20131125/acquire-and-release-fences-dont-work-the-way-youd-expect/)。atomic_thread_fenceimposes stronger synchronization constraints than an atomic store operation with the same std::memory_order. While an atomic store-release operation prevents all preceding reads and writes from moving past the store-release, anatomic_thread_fencewithmemory_order_releaseordering prevents all preceding reads and writes from moving past all subsequent stores.https://en.cppreference.com/w/cpp/atomic/atomic_thread_fence#Notes
举例说明:
release store
tmp = new Singleton; m_instance.store(tmp, std::memory_order_release);release fence
tmp = new Singleton; std::atomic_thread_fence(std::memory_order_release); m_instance.store(tmp, std::memory_order_relax);
上述两种写法都可以阻止
Singleton构造函数中的 store(假设Singleton构造函数中存在 store 操作)被 reorder 到对m_instance的 atomic store 之后。为什么说
atomic_thread_fence对 reordering 的限制要比使用相同 std::memory_order 的 atomic load/store 更强呢?如果我们把本例中的 release fence 替换为一个对其他 atomic object 的 release store,那么对m_instance的 atomic store 是可以被 reorder 到Singleton构造函数中的 store 之前的!tmp = new Singleton; g_dummy.store(0, std::memory_order_release); m_instance.store(tmp, std::memory_order_relax);P.S. 如果去看 clang 的实现的话,会发现 clang 为 built-in functions
__sync_synchronize(),__atomic_thread_fence(__ATOMIC_SEQ_CST)和__c11_atomic_thread_fence(__ATOMIC_SEQ_CST)生成的代码是一样的:
implement your own atomic_load/store on x86-64
#if defined(__x86_64__)
typedef unsigned char u8;
typedef unsigned short u16;
typedef unsigned int u32;
typedef unsigned long long u64;
typedef signed char s8;
typedef signed short s16;
typedef signed int s32;
typedef signed long long s64;
#if __LP64__
typedef unsigned long uptr;
typedef signed long sptr;
#else
typedef unsigned int uptr;
typedef signed int sptr;
#endif
template<typename T>
struct atomic {
typedef T Type;
volatile Type __attribute__((aligned(sizeof(Type)))) val_dont_use;
};
typedef atomic<s8> atomic_int8_t;
typedef atomic<u8> atomic_uint8_t;
typedef atomic<s16> atomic_int16_t;
typedef atomic<u16> atomic_uint16_t;
typedef atomic<s32> atomic_int32_t;
typedef atomic<u32> atomic_uint32_t;
typedef atomic<s64> atomic_int64_t;
typedef atomic<u64> atomic_uint64_t;
template<typename T>
inline typename T::Type atomic_load(
const volatile T *a, std::memory_order mo) {
assert(mo == std::memory_order_relaxed ||
mo == std::memory_order_consume ||
mo == std::memory_order_acquire ||
mo == std::memory_order_seq_cst);
assert(!((uptr)a % sizeof(*a)));
typename T::Type v;
if (mo == std::memory_order_relaxed) {
// On x86 naturally-aligned loads are atomic.
v = a->val_dont_use;
} else if (mo == std::memory_order_consume ||
mo == std::memory_order_acquire) {
// On x86 loads are implicitly acquire.
__asm__ __volatile__("" ::: "memory");
v = a->val_dont_use;
__asm__ __volatile__("" ::: "memory");
} else { // seq_cst
// On x86 plain MOV is enough for seq_cst load.
__asm__ __volatile__("" ::: "memory");
v = a->val_dont_use;
__asm__ __volatile__("" ::: "memory");
}
return v;
}
template<typename T>
inline void atomic_store(volatile T *a, typename T::Type v, std::memory_order mo) {
assert(mo == std::memory_order_relaxed ||
mo == std::memory_order_release ||
mo == std::memory_order_seq_cst);
assert(!((uptr)a % sizeof(*a)));
if (mo == std::memory_order_relaxed) {
// On x86 naturally-aligned stores are atomic.
a->val_dont_use = v;
} else if (mo == std::memory_order_release) {
// On x86 stores are implicitly release.
__asm__ __volatile__("" ::: "memory");
a->val_dont_use = v;
__asm__ __volatile__("" ::: "memory");
} else { // seq_cst
// On x86 stores are implicitly release.
// call __sync_synchronize() to flush store buffer.
__asm__ __volatile__("" ::: "memory");
a->val_dont_use = v;
__sync_synchronize();
}
}
#endif
quiz time
quiz-1
-- Initially --
std::atomic<int>x{0};
std::atomic<int>y{0};
-- Thread 1 --
x.store(1, std::memory_order_release);
-- Thread 2 --
y.store(2, std::memory_order_release);
-- Thread 3 --
int r1 = x.load(std::memory_order_acquire); // x first
int r2 = y.load(std::memory_order_acquire);
-- Thread 4 --
int r3 = y.load(std::memory_order_acquire); // y first
int r4 = x.load(std::memory_order_acquire);
分别从 C++ 标准的角度和 x86 的角度讨论是否可能出现 r1==1, r2==0 且 r3==2, r4==0 的情况。
quiz-2
-- Initially --
std::atomic<bool> x,y;
std::atomic<int> z;
x=false;
y=false;
z=0;
-- Thread 1 --
void write_x_then_y(){
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_relaxed); // 2
}
-- Thread 2 --
void read_y_then_x(){
while(!y.load(std::memory_order_relaxed)); // 3
if(x.load(std::memory_order_relaxed)) // 4
++z;
}
分别从 C++ 标准的角度和 x86 的角度讨论 z 是否一定不为 0。
quiz-3
atomic<int> x;
atomic<int> y;
y.store(1, memory_order_relaxed); //(1)
atomic_thread_fence(memory_order_seq_cst); //(2)
x.load(memory_order_relaxed); //(3)
上述代码是否可能被 reorder 为如下情况:
x.load(memory_order_relaxed); //(3)
y.store(1, memory_order_relaxed); //(1)
atomic_thread_fence(memory_order_seq_cst); //(2)
see also
C/C++11 mappings to processors. https://www.cl.cam.ac.uk/~pes20/cpp/cpp0xmappings.html
Jeff Preshing 关于 memory model 的一系列文章。 https://preshing.com/archives/
GCC 关于 C++11 memory model 的一系列文章。 https://gcc.gnu.org/wiki/Atomic/GCCMM
Peter Cordes 在 stack overflow 上的一些高质量回答
“Intel® 64 and IA-32 Architectures Software Developer Manuals” 和 “AMD64 Architecture Programmer’s Manual”