C++26 Hazard Pointers
Hazard pointers 一直在我的 todo list 上,但是一直没有时间和机会深入研究。最近听了 Maged M. Michael 关于 hazard pointers 的分享,正好趁此机会学习下 hazard pointers,整理成一篇博客。
Hazard pointers 由 Maged M. Michael 最早在 Hazard pointers: Safe memory reclamation for lock-free objects. IEEE Transactions on Parallel and Distributed Systems, 15(6):491–504, June 2004. 这篇论文中提出。根据 CppCon 2021: Hazard Pointer Synchronous reclamation beyond Concurrency TS2 的内容,Meta(Facebook) 至少在 2017 年就已经广泛使用 hazard pointers 了。Maged M. Michael 在提案 P2530 - Hazard Pointers for C++26 中建议将 hazard pointers 纳入 C++26,根据 https://github.com/cplusplus/papers/issues/1194 该提案已被接受,hazard pointers 确定包含在 C++26 中。
Safe Memory Reclamation
Reclamation 有“回收、再利用”的意思。Memory reclamation 指的是回收不再使用的内存资源,使其可以被重新分配和使用。
Safe memory reclamation(或简称为 safe-reclamation)技术的关键点是确定何时可以安全地回收特定分配的内存,以保证当存在一个线程访问某内存对象时,其他线程不会回收该内存对象。
Safe-reclamation techniques are most frequently used to straightforwardly resolve access-deletion races. —— C++ Standard
Read-copy-update(RCU) 和 hazard pointers 都是实现 safe-reclamation 的技术,它们都包含在 C++26 之中:
Folly 的 hazard pointers 代码注释中详细对比了不同的 safe-reclamation techniques 的优劣以及适用场景: https://github.com/facebook/folly/blob/v2025.01.06.00/folly/synchronization/Hazptr.h#L139
Hazard Pointers for C++26
A hazard pointer is a single-writer multi-reader pointer that can be owned by at most one thread at any time. Only the owner of the hazard pointer can set its value, while any number of threads may read its value. The owner thread sets the value of a hazard pointer to point to an object in order to indicate to concurrent threads — which may delete such an object — that the object is not yet safe to delete. —— C++ Standard
Overview
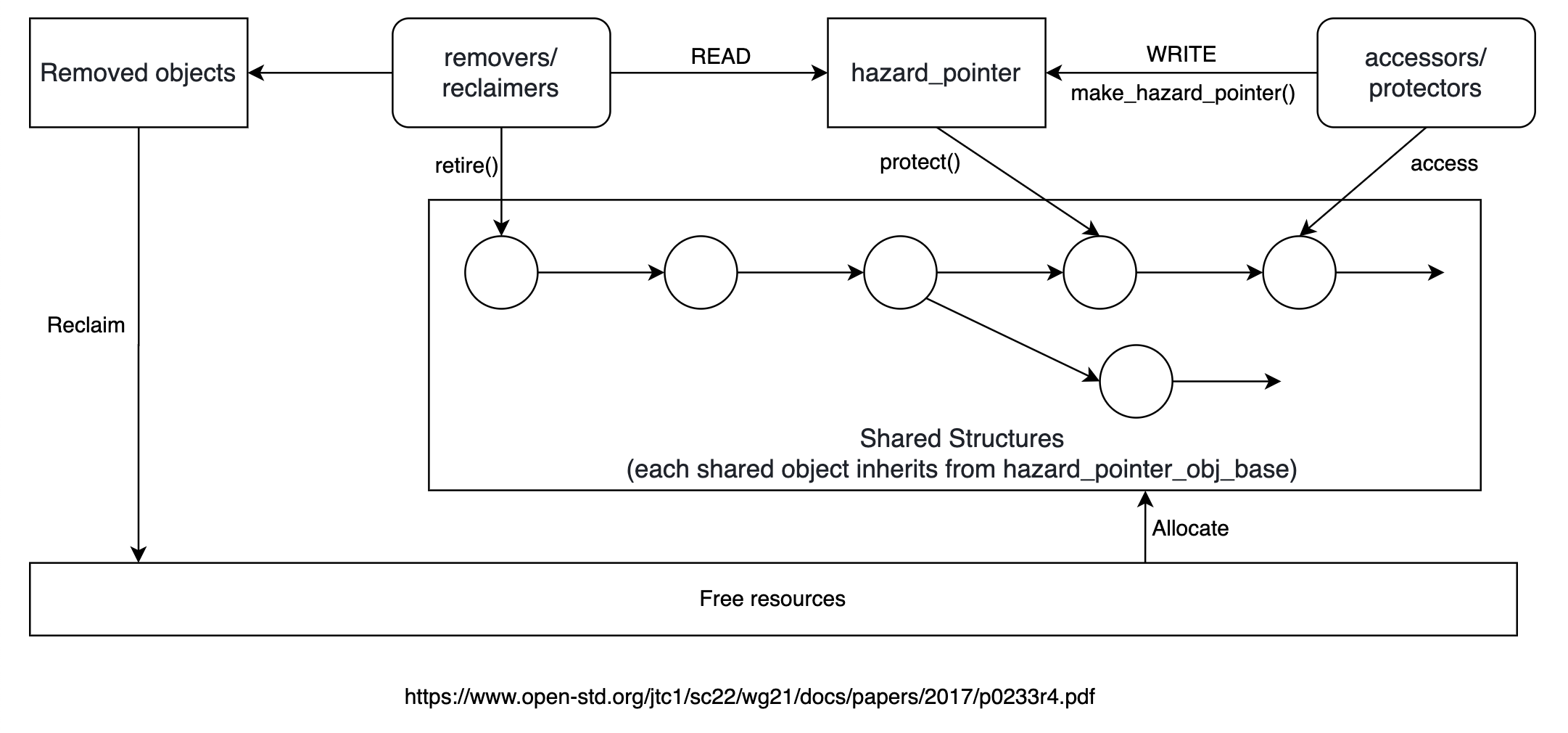
上图中 accessors/protectors 和 removers/reclaimers 指的是操作 shared objects 的线程,accessors/protectors 线程和 removers/reclaimers 线程是根据如何操作 shared objects 来分类的,accessors/protectors 线程和 removers/reclaimers 线程允许有交集(即同一个线程既是 accessor/protector 也是 remover/reclaimer)。
Hazard pointers library 提供了
make_hazard_pointer()函数,accessors/protectors 线程通过调用make_hazard_pointer()函数来创建一个hazard_pointer对象。函数
protect()是std::hazard_pointer的成员函数,accessor/protector 线程调用protect()函数将被保护的 shared object 的地址保存在该hazard_pointer中。protect()函数保证在该hazard_pointer的生命周期内被保护的 shared object 不会被 removers/reclaimers 线程回收,可以被安全地访问。Shared objects 需要继承
hazard_pointer_obj_base,函数retire()是hazard_pointer_obj_base的成员函数。当 removers/reclaimers 线程想回收某个 shared object 时,调用retire()函数将回收该 shared object 的责任移交给 hazard pointers library。Hazard pointers library 会在某一时刻检查是否此时没有任何hazard_pointer正在保护已经被retire()的 shared objects,如果是,那么就会回收这样的 shared objects。
Protection
某个 accessor/protector 线程调用 protect() 函数将被保护的 shared object 的地址保存在其持有的 hazard_pointer 中,就是在通知所有 removers/reclaimers 线程:只要该 accessor/protector 线程持有的 hazard_pointer 还在指向被保护的 shared object,那么就不要回收该 shared object。
Deferred Reclamation
当被 retire() 的对象的数量达到某个阈值时,hazard pointers library 会:
从保存所有 retired 对象的 retired list 中取出所有被
retire()的 shared objects。遍历所有的
hazard_pointers 将此时被保护的 shared objects 的地址保存在集合 hs 中。对于每一个被
retire()的 shared object,查看其地址是否在集合 hs 中:如果不在,那么回收该 shared object。
如果在,那么将该 shared object 放回 retired list 中。
Use Example
Read-Mostly Shared Data Without Hazard Pointers
使用 shared_mutex 配合 shared_lock 和 unique_lock 的实现。
struct Data { /* members */ }; Data* pdata_; shared_mutex m_; // Called frequently and in parallel template <typename U, typename Func> U reader_op(Func userFn) { shared_lock<shared_mutex> rlock(m_); // The user function userFn is not allowed // to block or call the writer function // because the read lock blocks writers. return userFn(pdata_); } // May be called concurrently with readers void writer(Data* newdata) { Data* old; { unique_lock<shared_mutex> wlock(m_); old = exchange(pdata_, newdata); } delete old; // Reclaim old immediately. }Read-Mostly Shared Data With Hazard Pointers
使用 hazard pointers 的实现。
struct Data : hazard_pointer_obj_base<Data> { /* members */ }; atomic<Data*> pdata_; // Called frequently and in parallel template <typename U, typename Func> U reader_op(Func userFn) { hazard_pointer h = make_hazard_pointer(); Data* p = h.protect(pdata_); // The user function userFn is allowed to block // and call the writer function because hazard // pointer protection does not block writers or // prevent the reclamation of unprotected objects. return userFn(p); // Safe to access *p. } // RAII end of protection. // May be called concurrently with readers void writer(Data* newdata) { Data* old = pdata_.exchange(newdata); old->retire(); // Reclaim old when unprotected. }
在上例中,相比基于 mutex/lock 的实现,基于 hazard pointers 的实现是允许 userFn 阻塞的,并且 hazard pointers 的 protect 非常快,通常在 nanoseconds 级(来源于 Maged M. Michael 的演讲)。
Wording
https://eel.is/c++draft/saferecl.hp 是 C++ 标准中有关 hazard pointers 的章节。
Header <hazard_pointer> synopsis
https://eel.is/c++draft/hazard.pointer.syn
<hazard_pointer> 头文件中提供了 hazard pointers 相关类和函数的声明:
namespace std {
// [saferecl.hp.base], class template hazard_pointer_obj_base
template<class T, class D = default_delete<T>> class hazard_pointer_obj_base;
// [saferecl.hp.holder], class hazard_pointer
class hazard_pointer;
// [saferecl.hp.holder.nonmem], non-member functions
hazard_pointer make_hazard_pointer();
void swap(hazard_pointer&, hazard_pointer&) noexcept;
}
Class hazard_pointer_obj_base
https://eel.is/c++draft/saferecl.hp.base
用户需要将自己的编写的类继承自 hazard_pointer_obj_base,才能获得基于 hazard pointer 的 safe memory reclamation 的支持。C++ 标准中称这样的类和类对象是 hazard-protectable 的。类 hazard_pointer_obj_base 提供了成员函数 retire(),用户通过调用该函数来将 hazard-protectable 对象标记为可被回收的,hazard pointers library 会在某一时刻回收该 retire() 的对象。
注意:hazard-protectable 对象只能调用一次 retire() 函数。一旦调用了retire() 函数,该对象就不应再被访问,因为一旦没有任何 hazard_pointer 保护它,memory reclamation 可能在任意时刻发生。应避免写出 double-retire, use-after-retire 的问题代码。
Class hazard_pointer
https://eel.is/c++draft/saferecl.hp.holder
hazard_pointer 也是 RAII 的应用,在 hazard_pointer 生命周期内,被 hazard_pointer 保护的对象的内存不会被回收,可以被安全地访问。
下面着重说下 hazard_pointer 的成员函数 protect(), try_protect(), reset_protection() 的语义:
成员函数
protect()的伪代码如下:template<class T> T* protect(const atomic<T*>& src) noexcept { T* ptr = src.load(memory_order::relaxed); while (!try_protect(ptr, src)) {} return ptr; }一直调用
try_protect()直至try_protect()成功,然后返回成功被保护的对象的内存地址。成员函数
try_protect()的伪代码如下:template<class T> bool try_protect(T*& ptr, const atomic<T*>& src) noexcept { T* old = ptr; reset_protection(old); ptr = src.load(memory_order::acquire); if (old != ptr) { reset_protection(nullptr); } return old == ptr; }注意:函数
try_protect()的第一个参数T*& ptr是引用传递,该函数会修改ptr参数的值。成员函数
reset_protection()的伪代码如下:template <typename T>void reset_protection(const T* ptr) noexcept { protected_ptr_.store(ptr, std::memory_order_release); } void reset_protection(std::nullptr_t = nullptr) noexcept { protected_ptr_.store(nullptr, std::memory_order_release); }reset_protection()的语义就是原子地更新当前hazard_pointer所保护的对象的地址,上述伪代码假设hazard_pointer存在一成员变量protected_ptr_存储当前受保护的对象的地址。
第一眼看到成员函数 protect() 和 try_protect() 的语义时,我的想法是怎么和 compare-and-swap (CAS) 的语义这么像。那么为什么成员函数 protect() 和 try_protect() 的语义需要这样设计?
考虑如下场景:
+-----------------------------------------------------------------------------------+
| struct Data : hazard_pointer_obj_base<Data> { /* members */ }; |
| |
| atomic<Data*> pdata_; |
+-------------------------------------------+---------------------------------------+
| Thread1 | Thread2 |
+-------------------------------------------+---------------------------------------+
| hazard_pointer h = make_hazard_pointer(); | |
| Data *ptr = pdata_.load(); | |
| | Data* old = pdata_.exchange(newdata); |
| | old->retire(); |
| h.reset_protection(ptr); | |
| userFn(ptr); | |
+-------------------------------------------+---------------------------------------+
Thread1 通过
make_hazard_pointer()创建一hazard_pointer,然后将pdata_指向的 Data 对象的内存地址保存在指针ptr中。Thread2 修改
pdata_使其指向新的 Data 对象,然后对原本pdata_指向的老 Data 对象old/ptr调用函数retire()。假设此时会触发 reclamation,那么因为此时没有任何hazard_pointer在保护old/ptr,所以old/ptr指向的内存会被释放回收。Thread1 通过
reset_protection将ptr保存的内存地址保存在hazard_pointer中。然后调用userFn(ptr)函数,在该函数中访问ptr指向的内存。但是此时ptr指向的内存已经被释放了。
因此,为了避免上述这类场景,try_protect(T*& ptr, const atomic<T*>& src) 在执行 reset_protection(p) 后,会检查此时 src 中保存的指针是否等于传给 reset_protection(p) 的参数 p。如果不相等,那么就修改参数 ptr 的值为此时 src 中保存的指针的值,并返回 false,说明 try_protect() 失败。protect() 会一直调用 try_protect() 直至 try_protect() 成功。
Hazard Pointer Extensions
P3135 - Hazard Pointer Extensions 中提出一些对 hazard pointers 的扩展,提议将 hazard pointer batches 和 cohort-based synchronous reclamation 这两项扩展包含在 C++29 中。
Batches of Hazard Pointers
支持高效地批量构造和销毁 hazard pointers,比较直观。
Interface
template <uint8_t N> class hazard_pointer_batch { hazard_pointer_batch() noexcept; hazard_pointer_batch(hazard_pointer_batch&&) noexcept; hazard_pointer_batch& operator=(hazard_pointer_batch&&) noexcept; ~hazard_pointer_batch(); [[nodiscard]] bool empty() const noexcept; hazard_pointer& operator[](uint8_t) noexcept; void swap(hazard_pointer_batch&) noexcept; }; template <uint8_t N> hazard_pointer_batch<N> make_hazard_pointer_batch(); template <uint8_t N> void swap(hazard_pointer_batch<N>&, hazard_pointer_batch<N>&) noexcept;Usage Example:
// C++26 hazard_pointer hp[3]; hp[0] = make_hazard_pointer(); hp[1] = make_hazard_pointer(); hp[2] = make_hazard_pointer(); // src is atomic<T*> T* ptr = hp[0].protect(src);// Batches of Hazard Pointers Extension hazard_pointer_batch<3> hp = make_hazard_pointer_batch<3>(); // src is atomic<T*> T* ptr = hp[0].protect(src);
Cohort-Based Synchronous Reclamation
C++26 的 hazard pointers 接口中,用户无法手动触发 reclamation,reclamation 的时刻没有保证,可能在任意时刻发生,即只支持 asynchronous reclamation。但是 Meta 在实践中发现,存在一些场景是需要 synchronous reclamation 支持的。建议观看 CppCon 2021: Hazard Pointer Synchronous reclamation beyond Concurrency TS2,了解 folly 对 hazard pointers 的 synchronous reclamation 支持的演变。
通过以下例子,了解什么场景下会需要 synchronous reclamation:
template <class T> class Container {
class Obj : hazard_pointer_obj_base<Obj> { T data; /* etc */ };
void insert(T data) {
Obj* obj = new Obj(data);
/* Insert obj in container */
}
void erase(Args args) {
Obj* obj = find(args);
/* Remove obj from container */
obj->retire();
}
};
class A {
// Deleter depends on resources with independent lifetime.
~A() { use_resource_XYZ(); }
};
make_resource_XYZ();
{
Container<A> container;
container.insert(a);
container.erase(a);
}
destroy_resource_XYZ();
// Obj containing 'a' may be not deleted yet.
上例中,class A 析构函数中会访问资源 XYZ,当 destroy_resource_XYZ() 资源 XYZ 被销毁后,尽管此时 container 中包含 a 的 Obj 已经被 retire() 了,因为在 C++26 中 hazard pointers 只支持 asynchronous reclamation,所以存在可能 Obj 在资源 XYZ 被销毁后才析构,导致访问已经被销毁的资源 XYZ。
为了解决上述问题,需要使得 hazard pointers 支持 synchronous reclamation。P3135 - Hazard Pointer Extensions 和 P3427 - Hazard Pointer Synchronous Reclamation 建议将 Hazard Pointer Synchronous Reclamation 扩展纳入在 C++29 中。提案中推荐的 synchronous reclamation 的实现方式就是通过 hazard_pointer_cohort。
hazard_pointer_cohort(可能的)接口如下:
class hazard_pointer_cohort {
hazard_pointer_cohort() noexcept;
hazard_pointer_cohort(const hazard_pointer_cohort&) = delete;
hazard_pointer_cohort(hazard_pointer_cohort&&) = delete;
hazard_pointer_cohort& operator=(const hazard_pointer_cohort&) = delete;
hazard_pointer_cohort& operator=(hazard_pointer_cohort&&) = delete;
~hazard_pointer_cohort();
};
template <class T, class D = default_delete<T>>
class hazard_pointer_obj_base {
public:
void retire_to_cohort(hazard_pointer_cohort&, D d = D()) noexcept;
};
hazard_pointer_cohort cohort_是所有执行retire_to_cohort(cohort_)的 retired 对象的集合一个 retired 对象最多属于一个
hazard_pointer_cohort,也可以不属于任何hazard_pointer_cohorthazard_pointer_cohort的析构函数保证,析构函数完成时,属于该hazard_pointer_cohort的所有 retired 对象的 deleters 也一定已经执行完成。
使用 hazard_pointer_cohort 改写上例。为 class Container 添加一个成员变量 hazard_pointer_cohort cohort_,Container::erase() 删除一个元素时不再是 obj->retire() 而是 obj->retire_to_cohort(cohort_)。这样,当 container 析构时,其成员变量 cohort_ 先析构,此时属于该 hazard_pointer_cohort 的所有 retired 的 Obj 对象的析构函数一定已经执行完成了。所以不会再出现 destroy_resource_XYZ() 资源 XYZ 被销毁后,Obj 对象的析构函数还在访问已经被销毁的资源 XYZ 的情况。
template <class T> class Container {
class Obj : hazard_pointer_obj_base<Obj> { T data; /* etc */ };
hazard_pointer_cohort cohort_;
void insert(T data) {
Obj* obj = new Obj(data);
/* Insert obj in container */
}
void erase(Args args) {
Obj* obj = find(args);
/* Remove obj from container */
obj->retire_to_cohort(cohort_);
}
};
class B {
// Deleter may depend on resources with independent lifetime.
~B() { use_resource_XYZ(); }
};
make_resource_XYZ();
{
Container<B> container;
container.insert(b);
container.erase(b);
}
// Obj containing 'b' was deleted.
destroy_resource_XYZ();
The ABA Problem: Hazard Pointers as a Solution
ABA problem 是实现 lock-free 数据结构时经常会遇到的问题。该问题的解决方案很多种,如 garbage collection, pointer tagging。本文介绍的 hazard pointers 也可以用于解决该问题。
接下来通过一个简单的 lock-free stack 实现来说明什么是 ABA 问题,然后说明如何通过 hazard pointers 来解决。
/* Naive lock-free stack which suffers from ABA problem.*/
template <typename T>
class Stack {
struct Node {
T val_;
Node* next_;
explicit Node(T v, Node* n = nullptr): val_(v), next_(n) {}
int value() const { return val_; }
Node* next() const { return next_; }
};
std::atomic<Node*> head_;
bool pop(T& val) {
Node* node;
while (true) {
node = head_.load();
if (node == nullptr) return false;
auto next = node->next();
// If head_ node is still the same, then assume no one has changed the stack.
// (That statement is not always true because of the ABA problem)
// Atomically replace top with next.
if (head_.compare_exchange_weak(node, next))
break;
// The stack has changed, start over.
}
val = node->value();
delete node;
return true;
}
void push(T val) {
auto node = new Node(val, head_.load());
// If head_ node is still the same, then assume no one has changed the stack.
// (That statement is not always true because of the ABA problem)
// Atomically replace top with obj.
while (!head_.compare_exchange_weak(node->next_, node)) {
// The stack has changed, try again.
}
}
};
考虑如下场景(注:下表中 A, B, C, D 指的是结点的内存地址而不是结点所保存的内容):
| Thread | Stack Before | Operation | Stack After |
|---|---|---|---|
T1 | head_ -> A -> B -> C | 执行 pop() 函数,在compare_exchange_weak() 执行之前,变量 node = A, next = B, | head_ -> A -> B -> C |
T2 | head_ -> A -> B -> C | 执行 pop() 函数,此时 A 内存被释放 | head_ -> B -> C |
T2 | head_ -> B -> C | 执行 pop() 函数,此时 B 内存被释放 | head_ -> C |
T2 | head_ -> C | 执行 push() 函数,新创建结点 D,恰好结点 D 申请到的内存是复用之前 A 已释放的内存,记作 D(A) | head_ -> D(A) -> C |
T1 | head_ -> D(A) -> C | 继续执行 compare_exchange_weak(),此时 Stack 的 head_ 是 D(A),变量 node = A, next = B,虽然 D 和 A 是不同的节点,但是因为 D 和 A 的内存地址是一样的,所以 compare_exchange_weak() 还是会将 head_ 设置为 B,但是此时 B 已经被释放了。 | undefined head_ 指向已释放的内存,C++ 中访问已释放的内存是 undefined behavior |
上述场景中 ABA 问题出现于:初始时 T1 第一次读取 head_ 其值为 A,然后 T2 执行两次 pop() 会依次将 head_ 的值修改为 B 和 C,T2 执行 push() 将 head_ 值修改回 A,T1 第二次读取 head_ ,发现其值依然是 A,即 T1 前后两次读取到的 head_ 值是一样的,T1 就认为在这两次读取之间 stack 没有被改变,但实际上 stack 已经被改变了。
通过 hazard pointers 来解决上述 lock-free stack 实现中的 ABA 问题:
/* Naive lock-free stack which NOT suffers from ABA problem.*/
template <typename T>
class Stack {
struct Node: public hazptr_obj_base<Node> {
T val_;
Node* next_;
explicit Node(T v, Node* n = nullptr): val_(v), next_(n) {}
int value() const { return val_; }
Node* next() const { return next_; }
};
std::atomic<Node*> head_;
bool pop(T& val) {
Node* node;
hazard_pointer h = make_hazard_pointer();
while (true) {
node = h.protect(head_);
if (node == nullptr) return false;
auto next = node->next();
// If head_ node is still the same, then assume no one has changed the stack.
// (That statement is not always true because of the ABA problem)
// Atomically replace top with next.
if (head_.compare_exchange_weak(node, next))
break;
// The stack has changed, start over.
}
val = node->value();
h.reset_protection();
node->retire();
return true;
}
void push(T val) {
auto node = new Node(val, head_.load();
// If head_ node is still the same, then assume no one has changed the stack.
// (That statement is not always true because of the ABA problem)
// Atomically replace top with obj.
while (!head_.compare_exchange_weak(node->next_, node)) {
// The stack has changed, try again.
}
};
上述代码通过在 pop() 函数中使用 hazard pointer 保护 head_ 来解决 ABA 问题。再次考虑之前会导致 ABA 问题的场景:使用 hazard pointer 后,因为 T1 在执行 pop() 函数 compare_exchange_weak() 语句之前创建了 hazard pointer 指向 A,所以 T2 执行 pop() 后并不会释放 A 的内存,因此后续 T2 执行 push() 函数新创建结点 D 时一定不会与 A 占用相同的内存地址。这样 T1 第二次读取到的 head_ 值不等于第一次读取到的 head_ 值 A 时,知道 stack 已经被改变过了,不再有 ABA 问题。
本节使用了简单的 lock-free stack 例子来说明 hazard pointers 可以解决 ABA 问题,下面两个参考链接中还以 lock-free unbounded queue 为例进行了说明:
Reference Implementation in Folly
本节解析 folly 的 hazard pointers 是如何实现的。
注:本节在介绍 folly 的 hazard pointers 实现时与真正的 folly 实现实际上是有一些细节上的不同的,主要是出于易于理解的考虑。本节也没有介绍 hazptr_obj_cohort 的相关实现,计划再写一篇博客专门介绍 hazptr_obj_cohort 的实现。
Hazard pointers 在 folly 实现与 C++ 标准的对应关系如下:
| namespace folly | namespace std |
|---|---|
hazptr_obj_base | hazard_pointer_obj_base |
hazptr_holder | hazard_pointer |
make_hazard_pointer() | make_hazard_pointer() |
hazptr_array | hazard_pointer_batch |
make_hazard_pointer_array | make_hazard_pointer_batch |
对于使用 hazard pointers 的用户来说,其直接交互的核心类就是 hazptr_holder 和 hazptr_obj_base。本节会围绕 hazptr_holder 和 hazptr_obj_base,介绍相关的关键函数实现,包括 hazptr_holder 的构造函数与析构函数,hazptr_holder::protect(),hazptr_obj_base::retire() 等。
Class hazptr_holder, hazptr_array
template <template <typename> class Atom>
class hazptr_holder {
hazptr_rec<Atom>* hprec_;
};
template <uint8_t N, template <typename> class Atom>
class hazptr_array {
aligned_hazptr_holder<Atom> raw_[N];
bool empty_{true};
};
template <template <typename> class Atom>
class hazptr_rec {
Atom<const void*> hazptr_{nullptr}; // the hazard pointer
hazptr_domain<Atom>* domain_;
hazptr_rec* next_; // Next in the main hazard pointer list. Immutable.
hazptr_rec* nextAvail_{nullptr}; // Next available hazard pointer.
};
folly::hazptr_holder对应std::hazard_pointer,对于 https://eel.is/c++draft/saferecl.hp.holder 中列举的std::hazard_pointer的成员函数,folly::hazptr_holder都存在对应实现。hazptr_holder只有一个成员变量hazptr_rec* hprec_(所以关键的实现其实是hazptr_rec类)。个人认为,
folly::hazptr_holder的命名更好,std::hazard_pointer的命名则容易造成误解。hazptr_array:optimized template for bulk construction and destruction of hazard pointers.folly::hazptr_array对应std::hazard_pointer_batch,folly::make_hazard_pointer_array()对应std::make_hazard_pointer_batch()。如前所述,hazptr_array是为了支持高效地批量构造和销毁hazptr_holder。hazptr_rec: contains the actual hazard pointer.hazptr_rec的命名是 hazard pointer record 的意思。hazptr_rec有四个成员变量:hazptr_,当调用hazptr_holder的成员函数protect(const Atom<T*>& src)时,就是将src.load()保存在hazptr_rec的成员变量hazptr_中,形成保护。domain_,指向hazptr_rec所属的hazptr_domain。在 folly 中只存在唯一的hazptr_domain,称作 global default domain,所以实际上所有的hazptr_rec的domain_都指向 global default domain。next_,next_指针在hazptr_rec创建时确定且不可变。属于同一hazptr_domain的所有的hazptr_rec通过next_指针形成了一个单向链表,该单向链表的头保存在hazptr_domain的成员变量hazptrs_中。因为 folly 中只存在唯一的 global default domain,所以 global default domain 的单向链表hazptrs_中记录着所有的hazptr_rec。nextAvail_,hazptr_domain的成员变量avail_以单向链表保存着可供申请的hazptr_recs,该单向链表就是通过hazptr_rec的成员变量nextAvail_指针连接在一起的。因此只有当hazptr_rec位于hazptr_domain的avail_单向链表中时nextAvail_指针才有意义。与next_不同的是,nextAvail_是可变的。
make_hazard_pointer(), make_hazard_pointer_array()
make_hazard_pointer(), make_hazard_pointer_array() 构造 hazptr_holder, hazptr_array 的流程如下图所示:
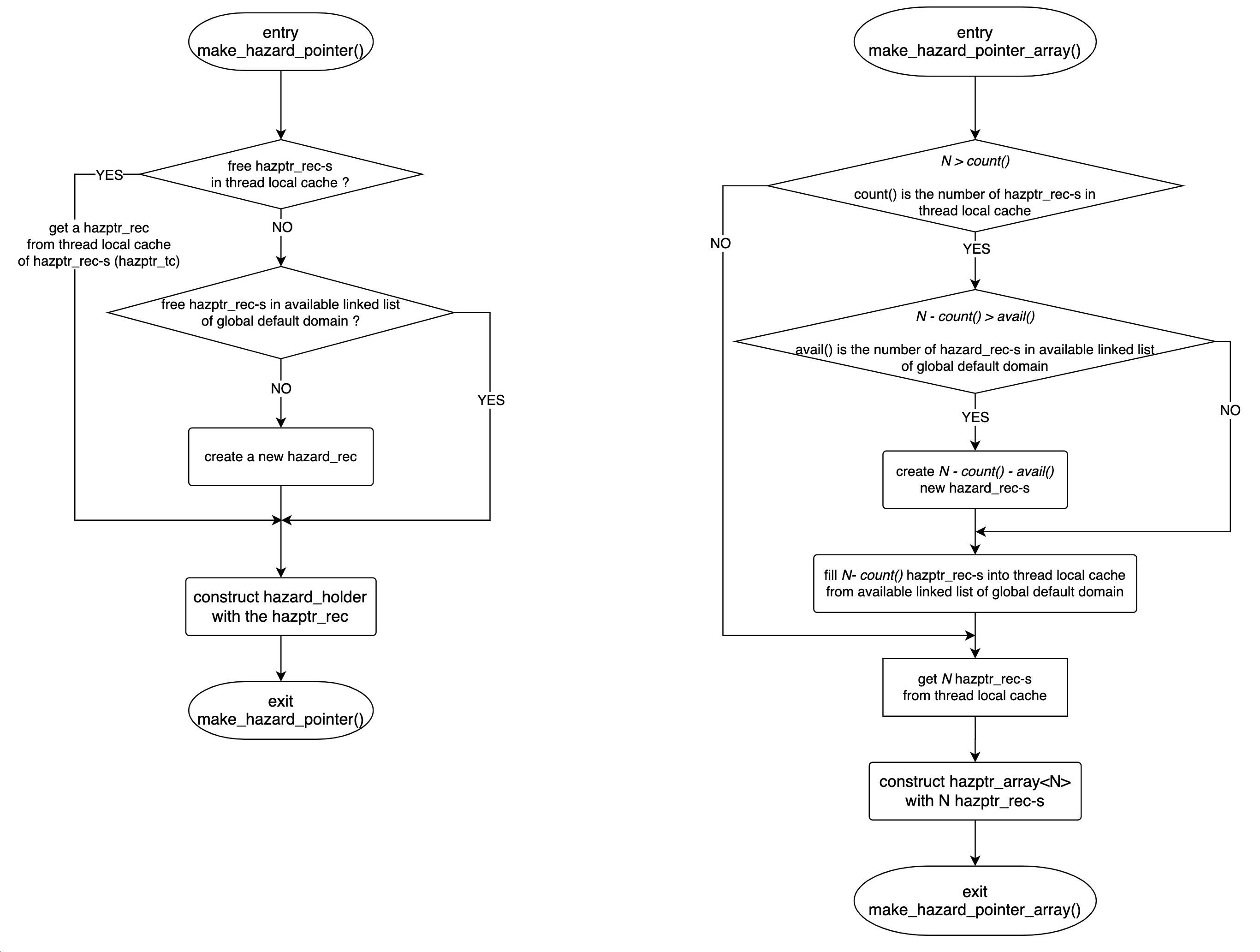
hazptr_holder 只有一个成员变量 hazptr_rec* hprec_,所以 make_hazard_pointer() 的关键就是如何申请一个 hazptr_rec 来创建 hazptr_holder:
查看
hazptr_tc即 thread cache of hazptr_rec-s 中是否有足够可用的hazptr_rec。如果是,那么就用hazptr_tc中可用的hazptr_rec创建一个hazptr_holder并返回。(class hazptr_tc将可用的hazptr_rec以数组保存在一成员变量中,最多保存kCapacity = 9个hazptr_rec)如果
hazptr_tc中没有足够的hazptr_rec可用,那么查看唯一的hazptr_domain即 global default domain 中是否有足够可用的hazptr_rec。如果是,那么使用可用的hazptr_rec创建一个hazptr_holder并返回。(class hazptr_domain的成员变量avail_以链表保存可用的hazptr_rec)如果 global default domain 也没有足够可用的
hazptr_rec,那么就需要创建新的hazptr_rec。申请内存,执行构造函数,将新创建的hazptr_rec记录到 global default domain 中,然后用新创建的hazptr_rec构造一个hazptr_holder并返回。
make_hazard_pointer_array() 需要 N 个 hazptr_rec 来创建一个 hazptr_array 并返回,流程与make_hazard_pointer() 类似,不再赘述。
~hazptr_holder(), ~hazptr_array()
hazptr_holder 和 hazptr_array<N> 的析构流程如下图所示:
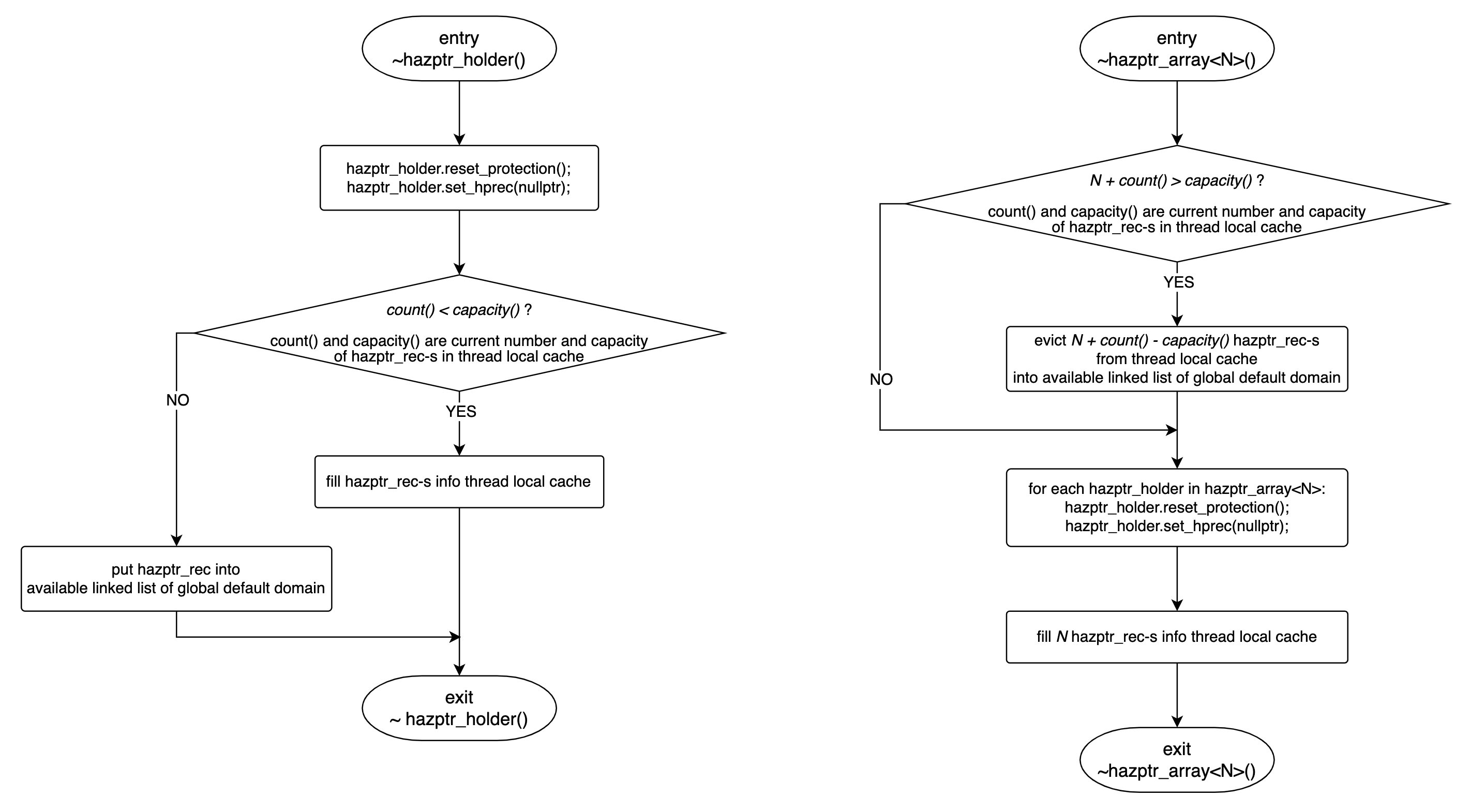
hazptr_array<N> 析构时不仅要释放 hazptr_rec,还要重置保护的对象地址:
hazptr_tc即 thread cache of hazptr_rec-s 中最多保存kCapacity = 9个hazptr_rec,而hazptr_array<N>中持有 N 个hazptr_rec,所以首先会检查N + count() > capacity(),即hazptr_tc是否有足够的空间保存hazptr_array<N>持有的 N 个hazptr_rec。如果
N + count() <= capacity(),那么直接跳转至 2。如果
N + count() > capacity(),那么将N + count() - capacity()个hazptr_rec从hazptr_tc归还至 global default domain 中。此时hazptr_tc中保存的hazptr_rec个数为new_count = capacity() - N。跳转至 2。
对于
hazptr_array<N>中的 N 个hazptr_holder,调用reset_protection()将hazptr_holder的hazptr_rec中保存的受保护的对象的地址设置为nullptr,调用set_hprec(nullptr)将hazptr_holder的成员变量hazptr_设置为nullptr。将
hazptr_array<N>中持有 N 个hazptr_rec保存至hazptr_tc中。
hazptr_holder 的析构流程更简单,不再赘述。
hazptr_holder::protect()
在之前的章节已经讨论过 C++ 标准中 hazard_pointer::protect() 的实现。Folly 中 hazptr_holder 的成员函数 protect() 的实现几乎是完全一致的。
这里出现的 asymmetric_thread_fence_light 是值得深入研究,也是包含在了 C++ Concurrency Technical Specification 2 中的。另外,强烈建议阅读 https://www.scylladb.com/2018/02/15/memory-barriers-seastar-linux/ 这篇文章进行了解。
template <typename T> T* protect(const Atom<T*>& src) noexcept {
T* ptr = src.load(std::memory_order_relaxed);
while (!try_protect(ptr, src)) {
/* Keep trying */
}
return ptr;
}
template<class T> bool try_protect(T*& ptr, const atomic<T*>& src) noexcept {
auto p = ptr;
reset_protection(p);
asymmetric_thread_fence_light(std::memory_order_seq_cst);
ptr = src.load(std::memory_order_acquire);
if (p != ptr) {
reset_protection(nullptr);
return false;
}
return true;
}
Class hazptr_obj_base
/** hazptr_obj_base */
template <
typename T,
template <typename> class Atom = std::atomic,
typename D = std::default_delete<T>>
class hazptr_obj_base;
/** hazard_pointer_obj_base
class template name consistent with standard proposal */
template <
typename T,
template <typename> class Atom = std::atomic,
typename D = std::default_delete<T>>
using hazard_pointer_obj_base = hazptr_obj_base<T, Atom, D>;
hazptr_obj_base: base template for objects protected by hazard pointers.
folly::hazptr_obj_base 对应 std::hazard_pointer_obj_base,folly 还为 hazptr_obj_base 提供了与 C++ 标准一致的别名 hazard_pointer_obj_base。
hazptr_obj_base 有四个成员变量 :
deleter_保存reclaim_用到的 deleter。reclaim_是一个函数指针,指向 reclaim 该对象时执行的函数。reclaim_指向的函数在调用retire()成员函数时设置,其内容就是对该hazptr_obj_base对象调用deleter_。next_。构造函数中将next_初始化为this。当一个hazptr_obj_base对象调用成员函数retire()后,会将该对象放入 global default domain 的 retired list 中,直至触发 reclamation 该对象被回收。当hazptr_obj_base对象位于 global default domain 的 retired list 时,next_指向的不再是自身,而是 retired list 中的下一个对象。调用成员函数retire()时会检测next_的值,如果此时next_ != this说明该hazptr_obj_base对象已经retire()了,发生了 double-retire bug。cohort_tag_,与hazptr_obj_cohort相关,本文先按下不表,会在另外一篇文章详解。
hazptr_obj_base::retire()
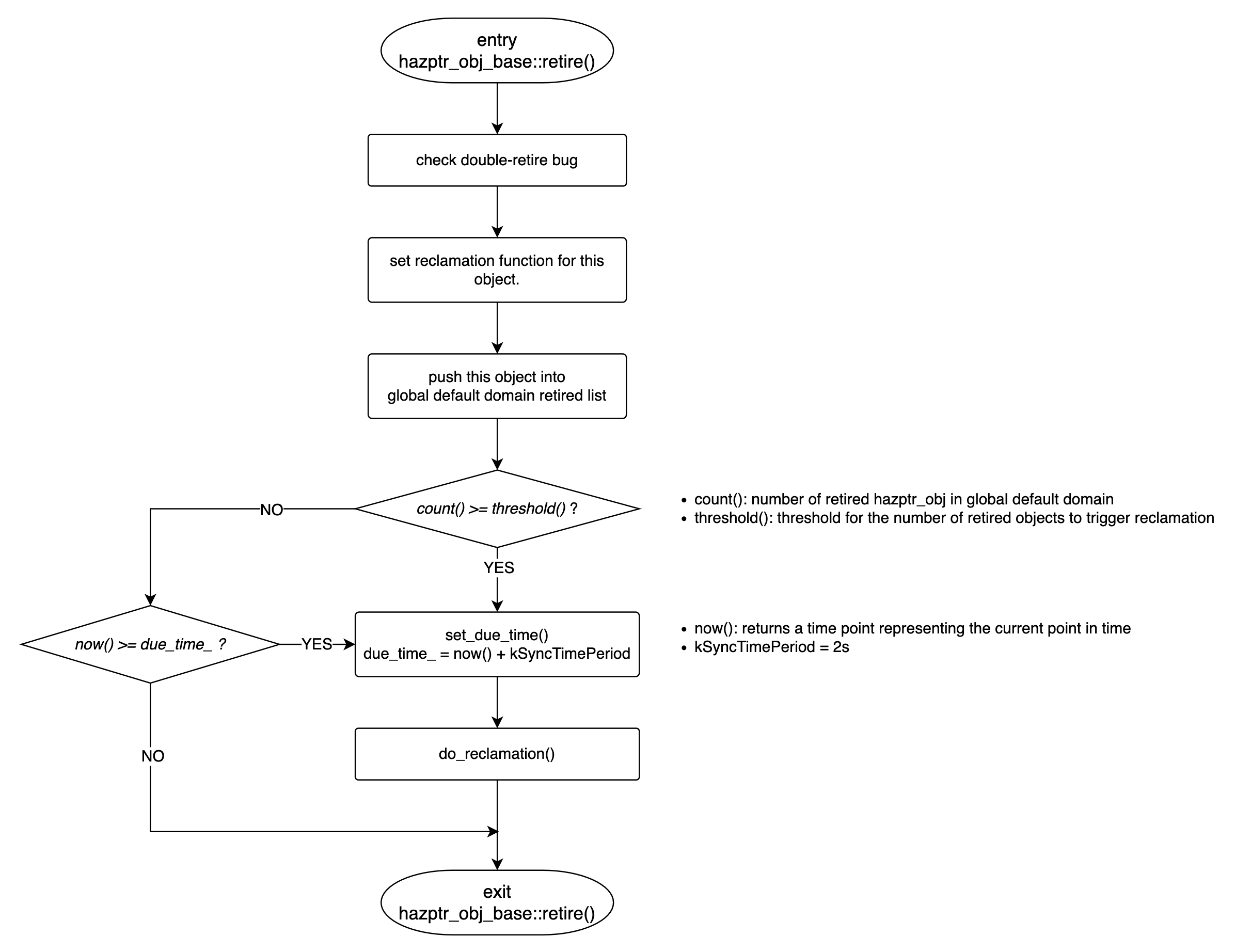
hazptr_obj_base::retire() 的实现很简单,首先检测是否触发了 double-retire bug,然后设置 reclaim_ 函数指针,最后调用成员函数 push_to_retired() 将当前 hazptr_obj_base 对象放入 global default domain 的 retired list 中。上图中也简单地给出了 reclamation 的相关逻辑(如什么时候会触发 reclamation),更详细的内容会在下一节分析 hazptr_domain 实现时进行介绍。
Class hazptr_domain, hazptr_tc
下图中描绘了用户代码在构造和析构 hazptr_holder 时是如何与 hazptr_tc 和 hazptr_domain 进行交互的,还给出了 hazptr_tc 的内容和 hazptr_domain 的关键数据结构。
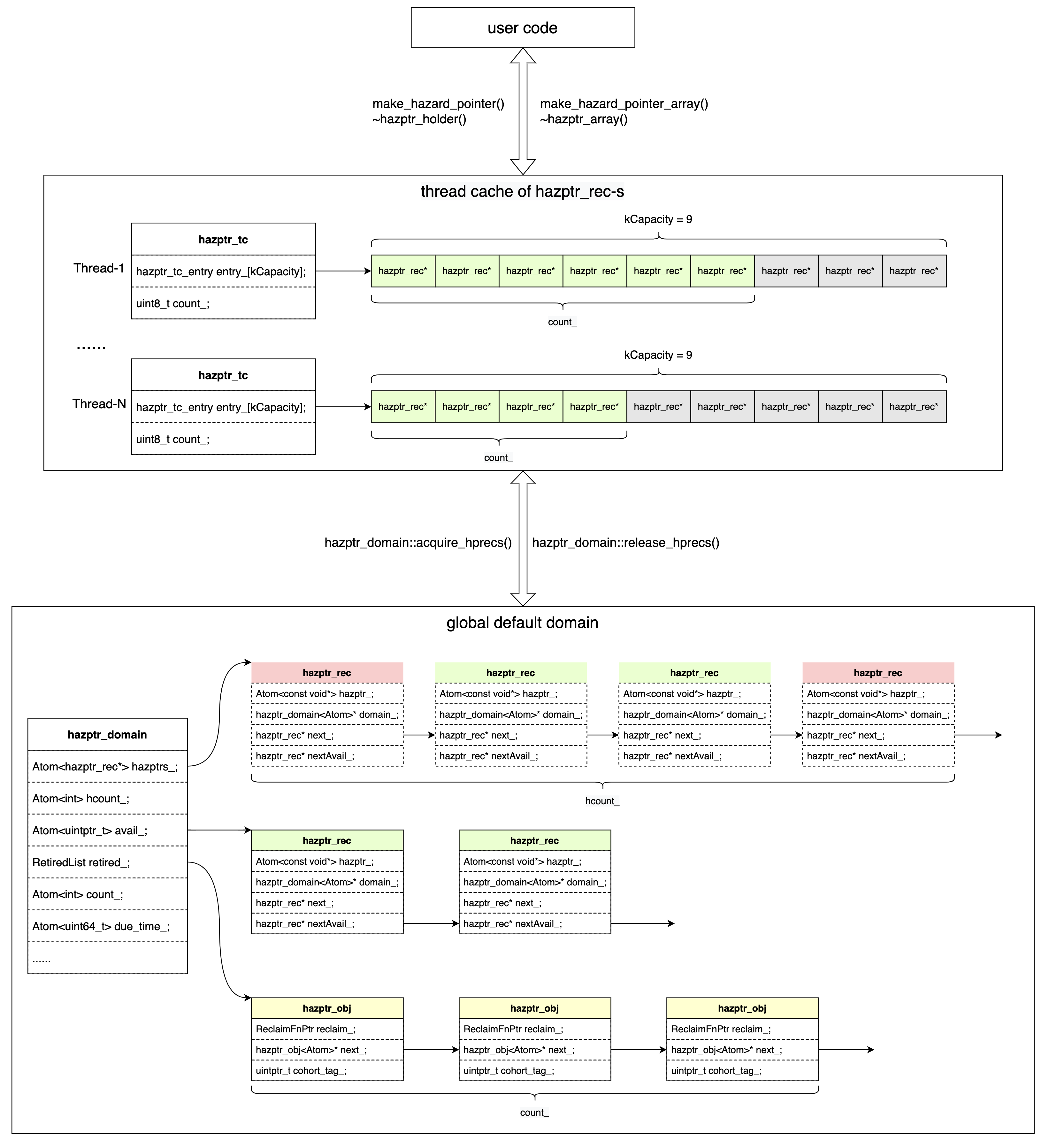
hazptr_tc: thread cache ofhazptr_recs that belong to the default domain.每个线程都有一个
hazptr_recs 的 cache,thread cache 中最多保存 kcapacity = 9 个hazptr_recs 。make_hazard_pointer()和make_hazard_pointer_array()都是优先从hazptr_tc获取hazptr_rec来构造hazptr_holder和hazptr_array的。如果hazptr_tc中的hazptr_rec不够用,则通过hazptr_domain::acquire_hprecs()从hazptr_domain中申请。如果hazptr_domain中的hazptr_rec依然不够用,那么hazptr_domain会申请内存创建新的hazptr_rec。hazptr_holder和hazptr_array<N>析构时也是优先将持有的hazptr_rec放入hazptr_tc中。如果超过了hazptr_tc的最大容量,则通过hazptr_domain::release_hprecs()返回给 global default domain。这种 thread-local cache 在内存分配器如 jemalloc, tcmalloc 中被广泛使用,算是一种常见的优化,通过减少对全局锁的竞争,获得更高的效率。
hazptr_domain: a domain manages a set of hazard pointers and a set of retired objects.如前所述,在 folly 实现中只存在全局唯一的
hazptr_domain称作 global default domain。hazptr_domain的关键成员变量:Atom<Rec*> hazptrs_,用单向链表记录着所有的hazptr_recs。归根结底,所有的hazptr_rec都是由 global default domain 创建的,因此 global default domain 可以很容易地在创建hazptr_rec后将其记录在hazptrs_链表中。并且hazptr_rec一旦被创建后是不会被析构的,只有在程序结束 global default domain 析构时,才会析构所有的hazptr_recs。(这里用“记录”是因为:对于hazptr_rec来说,其所有权并不是总在hazptr_domain中的,所有权可以在hazptr_holder中,可以在hazptr_tc中,可以在hazptr_domain的avail_链表中)Atom<int> hcount_,保存单向链表hazptrs_中hazptr_recs 的数量。Atom<uintptr_t> avail_,用单向链表保存所有可供申请(available)的hazptr_recs。RetiredList retiredlist_,保存 retired 的还没有被 reclaim 的hazptr_obj_base对象。(实际上 retired 的hazptr_obj_base对象保存的方式要更复杂,本文先按下不表,会在另外一篇文章详解)Atom<int> count_,保存retiredlist_中hazptr_obj_base对象数量。Atom<uint64_t> due_time_,时间戳。用于实现至少每隔 kSyncTimePeriod=2s 对retiredlist_中的对象执行一次 reclamation。
下面详细讨论下 reclamation。在什么条件下会触发 reclamation?阈值是怎么选择的?
当有新的hazptr_obj_base 对象被放入 global default domain 的 retiredlist_ 中时,会检查如下条件:
count_ >= threshold = max(1000, 2 * hcount_)距离上次 reclamation 的时间间隔超过了 2s
如果上述条件满足其一,就会触发 reclamation:首先,遍历单向链表 hazptrs_ 收集每一个 hazptr_rec 的成员变量 hazptr_,将此时正保护的对象的地址保存在集合 hs 中。然后,从 retiredlist_ 中取出所有 retired 对象,回收那些地址不在集合 hs 中的 retired 对象,将地址还在集合 hs 中的 retired 对象放回至 retiredlist_ 中。
如上所述,每次 reclamation 都需要遍历当前所有的 hazptr_recs。因为 hazptr_recs 的数量是 hcount_,所以这是一个时间复杂度为 O(hcount_) 的操作。通过积累一定数量的 retired 对象后再进行 reclamation,可以将一次 reclamation 的开销均摊到多个 retired 对象上。假设一次 reclamation 可以回收 K 个对象,那么均摊到每个对象的开销就是 O(hcount_/K)。当 K 与 hcount_ 成正比时,均摊复杂度就是常数级。
考虑条件一触发的 reclamation:
retiredlist_中 retiredhazptr_obj_base对象数量为count_,链表hazptrs_中hazptr_recs 的数量为hcount_。因为同一时刻每个
hazptr_rec最多只能保护一个hazptr_obj_base对象,那么hcount_个hazptr_rec最多保护hcount_个hazptr_obj_base对象,所以count_个 retired 对象中至少有count_ - hcount_个 retired 对象是没有被保护的。因为
count_ >= max(1000, 2 * hcount_)一定满足count_ >= 2 * hcount_,所以count_ - hcount_ >= hcount_,那么count_个 retired 对象中至少有hcount_个 retired 对象是没有被保护的。所以 reclamation 至少可以回收
hcount_个 retired 对象,这样每个 retired 对象的均摊回收成本是O(1)的。
条件二是对条件一的补充:确保所有 retired 对象最终被回收;如果单个 retired 对象占用的内存比较大,条件二的触发策略也可以防止大内存块滞留导致的高内存占用。
reclamation 越频繁,内存占用越少,CPU 开销则越大;反之,内存占用会变高,CPU 开销会变低,并且可能增加单次 reclamation 的延迟。
P.S.
阅读 folly hazard pointers 代码时的一些实现细节备注:
hazptr_domain::push_list()中asymmetric_thread_fence_light()与hazptr_domain::do_reclamation()中asymmetric_thread_fence_heavy()对应。考虑 thread1push_list, thread2do_reclamation的情况。hazptr_holder::try_protect()中asymmetric_thread_fence_light()与hazptr_domain::do_reclamation()中asymmetric_thread_fence_heavy()对应。考虑 thread1try_protect, thread2do_reclamation的情况。为什么在
check_count_threshold()时,如果count_ >= threshold会通过 CAS 将 count_ 设置为 0。而不是 reclaim 后才设置为 0。猜测是多线程check_threshold_and_reclaim()的场景,thread 1 将 count_ 设置为 0,thread 2 就不会同样执行到do_reclamation()了。
References
最后建议阅读下 David Goldblatt 在 https://www.reddit.com/r/cpp/comments/sywjf3/p2530_hazard_pointers_belong_in_the_standard/ 中的回复。特别是解释了 hazard pointer 到底是什么、什么样的场景需要 hazard pointers、为什么要将 hazard pointers 推进 C++ 标准等。
I think a lot of the descriptions are focused on the algorithmic side rather than the user experience side. Probably the best way to think of them as a user is in comparison with atomic_shared_ptr. Both have one main purpose: to ensure that an object won’t be deleted out from under you while you’re accessing it. atomic_shared_ptr, though, is slow to access, especially in concurrent settings. Hazard pointers are very quick to access, at the cost of delaying reclamation of pointed-to objects (objects accessed via shared_ptr always get destructed immediately, in the destructor of the last shared_ptr pointing to them; hazard pointer-protected objects get destroyed later, and potentially in a thread that never accessed them at all).
最后的最后,其实这篇博客断断续续写了很久很久,从 24 年底一直写到 25 年中。实际上我对这篇博客还不是很满意,因为 cohort-based synchronous reclamation 的实现是非常值得深入分析的,但是篇幅原因本文并没有涉及,计划后续再写一篇博客专门介绍 folly 对于 cohort-based synchronous reclamation 的实现。