SLP Vectorizer: Part 2 - Performance of LLVM SLP Vectorizer
在上一篇文章 SLP Vectorizer: Part 1 - Implementation in LLVM 中我们学习 LLVM 的 SLP Vectorizer 实现,本文基于 SPEC CPU 2017 来评估 SLP Vectorizer 的优化效果。
Introduction
在上一篇文章 SLP Vectorizer: Part 1 - Implementation in LLVM 的最后,我提到在 2013 LLVM Developers’ Meeting: “Vectorization in LLVM” 的最后有人问道:
Q: Do you happen to know how the speed ups from the two vectorizers (Loop Vectorizer and SLP Vectorizer) split out? One of them is more important or is it kind of equal?
A: The loop vectorizer is a lot more important.
Loop Vectorizer 于 LLVM 3.2 引入,于 LLVM 3.3 默认开启;SLP Vectorizer 于 LLVM 3.3 引入,于 LLVM 3.4 默认开启。现在距离 2013 年引入 SLP Vectorizer 已经有 10 年了,SLP Vectorizer 是否还是像 Nadav Rotem 在 2013 LLVM DevMtg 上说的那样(与 Loop Vectorizer 相比)只能带来很有限性能提升呢 。本着“实践是检验真理的唯一标准”的原则,本文通过实验来分析 SLP Vectorizer 能带来多少性能提升。
本文的测试基于如下环境:
LLVM trunk: b399c84
Processor: Intel(R) Xeon(R) Platinum 8260 CPU @ 2.40GHz (96 Cores)
Memory: 376 GB
Benchmark
LLVM test-suite 提供了 benchmark 程序可以测试运行时间、编译时间和代码大小等指标。例如,在 MicroBenchmarks/ 目录下就提供了基于 google-benchmark 编写的用于测试 SLP Vectorization, Loop Vectorization 的程序。LLVM test-suite 同样支持运行 SPEC 这样的 external suites。
本文就基于 SPEC CPU 2017 测试 SLP Vectorizer。
安装 SPEC CPU 2017,执行
$SPEC_CPU2017_PATH/install.sh会输出如下内容:SPEC CPU2017 Installation Top of the CPU2017 tree is '$SPEC_CPU2017_PATH' Installing FROM $SPEC_CPU2017_PATH Installing TO $SPEC_CPU2017_PATH Is this correct? (Please enter 'yes' or 'no')配置 llvm-test-suite 使用 SPEC CPU 2017 测试:
% git clone git@github.com:llvm/llvm-test-suite.git % mkdir llvm-test-suite-build % cd llvm-test-suite-build % cmake -GNinja -DCMAKE_C_COMPILER=$LLVM_BUILD_PATH/bin/clang \ -C../llvm-test-suite/cmake/caches/O3.cmake \ -DTEST_SUITE_BENCHMARKING_ONLY=ON \ -DTEST_SUITE_SUBDIRS=External \ -DTEST_SUITE_SPEC2017_ROOT=$SPEC_CPU2017_PATH/ \ -DTEST_SUITE_RUN_TYPE=test \ -DTEST_SUITE_COLLECT_STATS=ON \ -DTEST_SUITE_USE_PERF=ON \ -DCMAKE_EXPORT_COMPILE_COMMANDS=ON \ ../llvm-test-suite编译 SPEC CPU 2017 benchmark & 运行:
% ninja % llvm-lit -v -j 1 -o results.json .执行脚本 llvm-test-suite/utils/compare.py 来展示和比较运行结果:
# Make sure pandas and scipy are installed. Prepend `sudo` if necessary. % pip install pandas scipy # Show a single result file: % llvm-test-suite/utils/compare.py results.json # Compare two result files: % llvm-test-suite/utils/compare.py results_a.json results_b.json
Clang 在 O3 优化下,Loop Vectorizer 和 SLP Vectorizer 都会默认开启,并且是先执行 Loop Vectorizer 然后再执行 SLP Vectorizer,见 PassBuilderPipelines.cpp。Clang 提供了 -fno-vectorize 选项来关闭 Loop Vectorizer,-fno-slp-vectorize 选项关闭 SLP Vectorizer。
因此为了测试 SLP Vectorizer 的效果,进行了如下测试:
一同关闭 Loop Vectorizer 和 SLP Vectorizer 运行 SPEC 2017 即
O3 -fno-vectorize -fno-slp-vectorize开启 Loop Vectorizer 且关闭 SLP Vectorizer 运行 SPEC 2017 即
O3 -fno-vectorize一同开启 Loop Vectorizer 和 SLP Vectorizer 运行 SPEC 2017 即
O3
O3 -fno-vectorize -fno-slp-vectorize
关闭 Loop Vectorizer 和 SLP Vectorizer 运行 SPEC 2017 的结果如下:
Program exec_time
O3-no-LV-SLP.results
test-suite :: External/SPEC/CINT2017rate/525.x264_r/525.x264_r.test 44.94
test-suite :: External/SPEC/CINT2017speed/625.x264_s/625.x264_s.test 44.70
test-suite :: External/SPEC/CFP2017speed/619.lbm_s/619.lbm_s.test 18.72
test-suite :: External/SPEC/CINT2017speed/631.deepsjeng_s/631.deepsjeng_s.test 12.14
test-suite :: External/SPEC/CINT2017speed/657.xz_s/657.xz_s.test 11.19
test-suite :: External/SPEC/CINT2017rate/557.xz_r/557.xz_r.test 11.18
test-suite :: External/SPEC/CINT2017rate/500.perlbench_r/500.perlbench_r.test 10.54
test-suite :: External/SPEC/CINT2017speed/600.perlbench_s/600.perlbench_s.test 10.50
test-suite :: External/SPEC/CINT2017speed/605.mcf_s/605.mcf_s.test 9.78
test-suite :: External/SPEC/CINT2017rate/505.mcf_r/505.mcf_r.test 9.75
test-suite :: External/SPEC/CINT2017rate/531.deepsjeng_r/531.deepsjeng_r.test 7.21
test-suite :: External/SPEC/CINT2017rate/541.leela_r/541.leela_r.test 5.27
test-suite :: External/SPEC/CINT2017speed/641.leela_s/641.leela_s.test 5.27
test-suite :: External/SPEC/CFP2017rate/510.parest_r/510.parest_r.test 5.14
test-suite :: External/SPEC/CFP2017rate/508.namd_r/508.namd_r.test 5.05
test-suite :: External/SPEC/CINT2017rate/520.omnetpp_r/520.omnetpp_r.test 2.64
test-suite :: External/SPEC/CINT2017speed/620.omnetpp_s/620.omnetpp_s.test 2.61
test-suite :: External/SPEC/CFP2017rate/519.lbm_r/519.lbm_r.test 2.27
test-suite :: External/SPEC/CFP2017rate/544.nab_r/544.nab_r.test 1.57
test-suite :: External/SPEC/CFP2017speed/644.nab_s/644.nab_s.test 1.56
test-suite :: External/SPEC/CFP2017rate/511.povray_r/511.povray_r.test 0.32
test-suite :: External/SPEC/CFP2017rate/526.blender_r/526.blender_r.test 0.17
test-suite :: External/SPEC/CINT2017speed/623.xalancbmk_s/623.xalancbmk_s.test 0.06
test-suite :: External/SPEC/CINT2017rate/523.xalancbmk_r/523.xalancbmk_r.test 0.06
test-suite :: External/SPEC/CFP2017speed/638.imagick_s/638.imagick_s.test 0.01
test-suite :: External/SPEC/CFP2017rate/538.imagick_r/538.imagick_r.test 0.01
test-suite :: External/SPEC/CFP2017rate/997.specrand_fr/997.specrand_fr.test 0.01
test-suite :: External/SPEC/CINT2017rate/999.specrand_ir/999.specrand_ir.test 0.01
test-suite :: External/SPEC/CFP2017speed/996.specrand_fs/996.specrand_fs.test 0.01
test-suite :: External/SPEC/CINT2017speed/998.specrand_is/998.specrand_is.test 0.01
test-suite :: External/SPEC/CINT2017rate/502.gcc_r/502.gcc_r.test 0.01
test-suite :: External/SPEC/CINT2017speed/602.gcc_s/602.gcc_s.test 0.0
O3 -fno-slp-vectorize
开启 Loop Vectorizer 且关闭 SLP Vectorizer 运行 SPEC 2017 的结果如下:
Program exec_time
O3-no-SLP.results
test-suite :: External/SPEC/CINT2017speed/625.x264_s/625.x264_s.test 38.35
test-suite :: External/SPEC/CINT2017rate/525.x264_r/525.x264_r.test 38.31
test-suite :: External/SPEC/CFP2017speed/619.lbm_s/619.lbm_s.test 18.44
test-suite :: External/SPEC/CINT2017speed/631.deepsjeng_s/631.deepsjeng_s.test 12.01
test-suite :: External/SPEC/CINT2017rate/500.perlbench_r/500.perlbench_r.test 11.33
test-suite :: External/SPEC/CINT2017speed/600.perlbench_s/600.perlbench_s.test 11.29
test-suite :: External/SPEC/CINT2017rate/557.xz_r/557.xz_r.test 11.14
test-suite :: External/SPEC/CINT2017speed/657.xz_s/657.xz_s.test 11.12
test-suite :: External/SPEC/CINT2017rate/505.mcf_r/505.mcf_r.test 10.66
test-suite :: External/SPEC/CINT2017speed/605.mcf_s/605.mcf_s.test 10.59
test-suite :: External/SPEC/CINT2017rate/531.deepsjeng_r/531.deepsjeng_r.test 7.21
test-suite :: External/SPEC/CINT2017rate/541.leela_r/541.leela_r.test 5.29
test-suite :: External/SPEC/CINT2017speed/641.leela_s/641.leela_s.test 5.29
test-suite :: External/SPEC/CFP2017rate/510.parest_r/510.parest_r.test 5.01
test-suite :: External/SPEC/CFP2017rate/508.namd_r/508.namd_r.test 4.99
test-suite :: External/SPEC/CINT2017speed/620.omnetpp_s/620.omnetpp_s.test 2.66
test-suite :: External/SPEC/CINT2017rate/520.omnetpp_r/520.omnetpp_r.test 2.65
test-suite :: External/SPEC/CFP2017rate/519.lbm_r/519.lbm_r.test 2.25
test-suite :: External/SPEC/CFP2017speed/644.nab_s/644.nab_s.test 1.58
test-suite :: External/SPEC/CFP2017rate/544.nab_r/544.nab_r.test 1.58
test-suite :: External/SPEC/CFP2017rate/511.povray_r/511.povray_r.test 0.32
test-suite :: External/SPEC/CFP2017rate/526.blender_r/526.blender_r.test 0.17
test-suite :: External/SPEC/CINT2017speed/623.xalancbmk_s/623.xalancbmk_s.test 0.06
test-suite :: External/SPEC/CINT2017rate/523.xalancbmk_r/523.xalancbmk_r.test 0.06
test-suite :: External/SPEC/CFP2017rate/538.imagick_r/538.imagick_r.test 0.01
test-suite :: External/SPEC/CFP2017speed/638.imagick_s/638.imagick_s.test 0.01
test-suite :: External/SPEC/CFP2017speed/996.specrand_fs/996.specrand_fs.test 0.01
test-suite :: External/SPEC/CINT2017speed/998.specrand_is/998.specrand_is.test 0.01
test-suite :: External/SPEC/CFP2017rate/997.specrand_fr/997.specrand_fr.test 0.01
test-suite :: External/SPEC/CINT2017rate/999.specrand_ir/999.specrand_ir.test 0.01
test-suite :: External/SPEC/CINT2017speed/602.gcc_s/602.gcc_s.test 0.01
test-suite :: External/SPEC/CINT2017rate/502.gcc_r/502.gcc_r.test 0.01
O3
一同开启 Loop Vectorizer 和 SLP Vectorizer 运行 SPEC 2017 的结果如下:
Program exec_time
O3.results
test-suite :: External/SPEC/CINT2017speed/625.x264_s/625.x264_s.test 24.54
test-suite :: External/SPEC/CINT2017rate/525.x264_r/525.x264_r.test 24.52
test-suite :: External/SPEC/CFP2017speed/619.lbm_s/619.lbm_s.test 18.90
test-suite :: External/SPEC/CINT2017speed/631.deepsjeng_s/631.deepsjeng_s.test 12.11
test-suite :: External/SPEC/CINT2017rate/557.xz_r/557.xz_r.test 11.24
test-suite :: External/SPEC/CINT2017speed/657.xz_s/657.xz_s.test 11.22
test-suite :: External/SPEC/CINT2017rate/500.perlbench_r/500.perlbench_r.test 10.68
test-suite :: External/SPEC/CINT2017speed/600.perlbench_s/600.perlbench_s.test 10.57
test-suite :: External/SPEC/CINT2017rate/505.mcf_r/505.mcf_r.test 10.52
test-suite :: External/SPEC/CINT2017speed/605.mcf_s/605.mcf_s.test 10.51
test-suite :: External/SPEC/CINT2017rate/531.deepsjeng_r/531.deepsjeng_r.test 7.21
test-suite :: External/SPEC/CINT2017rate/541.leela_r/541.leela_r.test 5.30
test-suite :: External/SPEC/CINT2017speed/641.leela_s/641.leela_s.test 5.29
test-suite :: External/SPEC/CFP2017rate/510.parest_r/510.parest_r.test 5.09
test-suite :: External/SPEC/CFP2017rate/508.namd_r/508.namd_r.test 4.25
test-suite :: External/SPEC/CINT2017rate/520.omnetpp_r/520.omnetpp_r.test 2.63
test-suite :: External/SPEC/CINT2017speed/620.omnetpp_s/620.omnetpp_s.test 2.61
test-suite :: External/SPEC/CFP2017rate/519.lbm_r/519.lbm_r.test 2.28
test-suite :: External/SPEC/CFP2017rate/544.nab_r/544.nab_r.test 1.55
test-suite :: External/SPEC/CFP2017speed/644.nab_s/644.nab_s.test 1.52
test-suite :: External/SPEC/CFP2017rate/511.povray_r/511.povray_r.test 0.33
test-suite :: External/SPEC/CFP2017rate/526.blender_r/526.blender_r.test 0.17
test-suite :: External/SPEC/CINT2017speed/623.xalancbmk_s/623.xalancbmk_s.test 0.06
test-suite :: External/SPEC/CINT2017rate/523.xalancbmk_r/523.xalancbmk_r.test 0.06
test-suite :: External/SPEC/CFP2017speed/638.imagick_s/638.imagick_s.test 0.01
test-suite :: External/SPEC/CFP2017rate/538.imagick_r/538.imagick_r.test 0.01
test-suite :: External/SPEC/CFP2017speed/996.specrand_fs/996.specrand_fs.test 0.01
test-suite :: External/SPEC/CFP2017rate/997.specrand_fr/997.specrand_fr.test 0.01
test-suite :: External/SPEC/CINT2017rate/999.specrand_ir/999.specrand_ir.test 0.01
test-suite :: External/SPEC/CINT2017speed/998.specrand_is/998.specrand_is.test 0.01
test-suite :: External/SPEC/CINT2017rate/502.gcc_r/502.gcc_r.test 0.01
test-suite :: External/SPEC/CINT2017speed/602.gcc_s/602.gcc_s.test 0.01
Performance: Loop Vectorizer v.s. SLP Vectorizer
通过比较 O3 -fno-vectorize -fno-slp-vectorize, O3 -fno-vectorize 和 O3 这 3 次运行,对比 Loop Vectorizer 和 SLP Vectorizer 的优化效果。
Loop Vectorizer
% python3 ~/llvm-test-suite/utils/compare.py \ O3-no-LV-SLP.results.json O3-no-SLP.results.json \ --no-abs-sort --absolute-diff --filter-short=1 Tests: 32 Short Running: 12 (filtered out) Remaining: 20 Metric: exec_time Program exec_time O3-no-LV-SLP.results O3-no-SLP.results diff 525.x264_r 44.94 38.31 -6.64 625.x264_s 44.70 38.35 -6.35 505.mcf_r 9.75 10.66 0.91 605.mcf_s 9.78 10.59 0.82 600.perlbench_s 10.50 11.29 0.79 500.perlbench_r 10.54 11.33 0.79 619.lbm_s 18.72 18.44 -0.28 510.parest_r 5.14 5.01 -0.13 631.deepsjeng_s 12.14 12.01 -0.13 657.xz_s 11.19 11.12 -0.07 508.namd_r 5.05 4.99 -0.06 620.omnetpp_s 2.61 2.66 0.05 557.xz_r 11.18 11.14 -0.05 519.lbm_r 2.27 2.25 -0.02 644.nab_s 1.56 1.58 0.02SLP Vectorizer
% python3 ~/llvm-test-suite/utils/compare.py \ O3-no-SLP.results.json O3.results.json \ --minimal-names --no-abs-sort --absolute-diff --filter-short=1 Tests: 32 Short Running: 12 (filtered out) Remaining: 20 Metric: exec_time Program exec_time O3-no-SLP.results O3.results diff 625.x264_s 38.35 24.54 -13.81 525.x264_r 38.31 24.52 -13.79 508.namd_r 4.99 4.25 -0.73 600.perlbench_s 11.29 10.57 -0.72 500.perlbench_r 11.33 10.68 -0.65 619.lbm_s 18.44 18.90 0.47 505.mcf_r 10.66 10.52 -0.14 557.xz_r 11.14 11.24 0.11 657.xz_s 11.12 11.22 0.10 631.deepsjeng_s 12.01 12.11 0.10 510.parest_r 5.01 5.09 0.09 605.mcf_s 10.59 10.51 -0.08 644.nab_s 1.58 1.52 -0.06 620.omnetpp_s 2.66 2.61 -0.04 544.nab_r 1.58 1.55 -0.03
根据上述结果,Loop Vectorizer 和 SLP Vectorizer 的优化效果在 x264 上的效果最明显:
开启 Loop Vectorizer,将运行时间从 44.94s(44.70s) 优化到 38.31s(38.35s),优化了 6.64s(6.35s),有相对 14.8%(14.2%) 的收益
在开启 Loop Vectorizer 的基础上再开启 SLP Vectorizer,将运行时间从 38.31s(38.35s) 优化到 24.52s(24.54s),优化了 13.79s(13.81s),有相对 36.0% 的收益
至少在 x264 上 SLP Vectorizer 带来的性能提升是远大于 Loop Vectorizer 的!
Case study: x264
本节尝试分析 Loop Vectorizer 和 SLP Vectorizer 为 x264 带来的性能提升的来源。
查看 llvm-test-suite-build/test.log 找到运行 x264 执行的命令为:625.x264_s --dumpyuv 50 --frames 156 -o BuckBunny_New.264 BuckBunny.yuv 1280x720
通过 perf 对比不同编译选项编译出来的 x264 的运行时 profile 信息,分析 Loop Vectorizer 和 SLP Vectorizer 为 x264 带来的性能提升的来源。
% cd llvm-test-suite-build/External/SPEC/CINT2017speed/625.x264_s/run_test
% perf record --call-graph=dwarf ../625.x264_s --dumpyuv 50 --frames 156 -o BuckBunny_New.264 BuckBunny.yuv 1280x720
% perf report --no-children
perf report: x264 built with
O3 -fno-vectorize -fno-slp-vectorizeSamples: 183K of event 'cycles', Event count (approx.): 139996467543 Overhead Command Shared Object Symbol + 18.81% 625.x264_s 625.x264_s [.] x264_pixel_sad_16x16 + 15.28% 625.x264_s 625.x264_s [.] get_ref + 14.75% 625.x264_s 625.x264_s [.] x264_pixel_satd_8x4 + 5.57% 625.x264_s 625.x264_s [.] x264_pixel_sad_x4_8x8 + 5.07% 625.x264_s 625.x264_s [.] quant_4x4 + 4.59% 625.x264_s 625.x264_s [.] mc_chroma + 2.97% 625.x264_s 625.x264_s [.] x264_pixel_sad_x3_8x8 + 2.38% 625.x264_s 625.x264_s [.] pixel_hadamard_ac + 1.89% 625.x264_s 625.x264_s [.] quant_trellis_cabac + 1.79% 625.x264_s 625.x264_s [.] x264_pixel_sad_8x8 + 1.71% 625.x264_s 625.x264_s [.] refine_subpel + 1.52% 625.x264_s 625.x264_s [.] x264_me_search_ref + 1.45% 625.x264_s 625.x264_s [.] hpel_filter + 1.45% 625.x264_s 625.x264_s [.] x264_pixel_sad_16x8 + 1.16% 625.x264_s 625.x264_s [.] quant_8x8 + 1.09% 625.x264_s 625.x264_s [.] sub4x4_dctperf report: x264 built with
O3 -fno-slp-vectorizeSamples: 157K of event 'cycles', Event count (approx.): 120606957278 Overhead Command Shared Object Symbol + 22.12% 625.x264_s 625.x264_s [.] x264_pixel_sad_16x16 + 16.96% 625.x264_s 625.x264_s [.] x264_pixel_satd_8x4 + 9.11% 625.x264_s 625.x264_s [.] get_ref + 6.40% 625.x264_s 625.x264_s [.] x264_pixel_sad_x4_8x8 + 5.26% 625.x264_s 625.x264_s [.] mc_chroma + 3.46% 625.x264_s 625.x264_s [.] x264_pixel_sad_x3_8x8 + 2.39% 625.x264_s 625.x264_s [.] pixel_hadamard_ac + 2.15% 625.x264_s 625.x264_s [.] quant_trellis_cabac + 2.13% 625.x264_s 625.x264_s [.] x264_pixel_sad_8x8 + 1.95% 625.x264_s 625.x264_s [.] refine_subpel + 1.81% 625.x264_s 625.x264_s [.] quant_4x4 + 1.75% 625.x264_s 625.x264_s [.] x264_me_search_ref + 1.68% 625.x264_s 625.x264_s [.] x264_pixel_sad_16x8 + 1.19% 625.x264_s 625.x264_s [.] sub4x4_dctperf report: x264 built with
O3Samples: 100K of event 'cycles', Event count (approx.): 77140113982 Overhead Command Shared Object Symbol + 26.50% 625.x264_s 625.x264_s [.] x264_pixel_satd_8x4 + 13.90% 625.x264_s 625.x264_s [.] get_ref + 8.13% 625.x264_s 625.x264_s [.] mc_chroma + 3.81% 625.x264_s 625.x264_s [.] pixel_hadamard_ac + 3.41% 625.x264_s 625.x264_s [.] quant_trellis_cabac + 3.41% 625.x264_s 625.x264_s [.] x264_pixel_sad_16x16 + 2.98% 625.x264_s 625.x264_s [.] refine_subpel + 2.84% 625.x264_s 625.x264_s [.] quant_4x4 + 2.32% 625.x264_s 625.x264_s [.] x264_me_search_ref + 1.86% 625.x264_s 625.x264_s [.] sub4x4_dct + 1.48% 625.x264_s 625.x264_s [.] pixel_avg_weight_wxh + 1.41% 625.x264_s 625.x264_s [.] hpel_filter + 1.06% 625.x264_s 625.x264_s [.] x264_pixel_satd_4x4 + 0.93% 625.x264_s 625.x264_s [.] x264_pixel_sad_x4_8x8
Loop Vectorizer
通过 perf 信息,可以看到开启 Loop Vectorizer 后 x264 的性能提升主要来自于对 get_ref() 函数的优化。
函数 get_ref() 的定义位于 x264_src/common/mc.c 中,源代码如下:
static uint8_t *get_ref( uint8_t *dst, int *i_dst_stride,
uint8_t *src[4], int i_src_stride,
int mvx, int mvy,
int i_width, int i_height, const x264_weight_t *weight )
{
int qpel_idx = ((mvy&3)<<2) + (mvx&3);
int offset = (mvy>>2)*i_src_stride + (mvx>>2);
uint8_t *src1 = src[hpel_ref0[qpel_idx]] + offset + ((mvy&3) == 3) * i_src_stride;
if( qpel_idx & 5 ) /* qpel interpolation needed */
{
uint8_t *src2 = src[hpel_ref1[qpel_idx]] + offset + ((mvx&3) == 3);
pixel_avg( dst, *i_dst_stride, src1, i_src_stride,
src2, i_src_stride, i_width, i_height );
if( weight->weightfn )
mc_weight( dst, *i_dst_stride, dst, *i_dst_stride, weight, i_width, i_height );
return dst;
}
else if( weight->weightfn )
{
mc_weight( dst, *i_dst_stride, src1, i_src_stride, weight, i_width, i_height );
return dst;
}
else
{
*i_dst_stride = i_src_stride;
return src1;
}
}
表面上看函数 get_ref() 的定义,应该是没有 Loop Vectorizer 的向量化机会的,那为什么开启 Loop Vectorizer 后对 get_ref() 函数优化有性能提升呢?答案是编译优化先将 get_ref() 函数中对 pixel_avg() 函数和 mc_weight() 函数的调用 inline 了,然后 inline 后的get_ref() 函数被 Loop Vectorizer 向量化了。
pixel_avg() 函数和 mc_weight() 函数的定义如下:
static inline void pixel_avg( uint8_t *dst, int i_dst_stride,
uint8_t *src1, int i_src1_stride,
uint8_t *src2, int i_src2_stride,
int i_width, int i_height )
{
for( int y = 0; y < i_height; y++ )
{
for( int x = 0; x < i_width; x++ )
dst[x] = ( src1[x] + src2[x] + 1 ) >> 1;
dst += i_dst_stride;
src1 += i_src1_stride;
src2 += i_src2_stride;
}
}
#define opscale(x) dst[x] = x264_clip_uint8( ((src[x] * weight->i_scale + (1<<(weight->i_denom - 1))) >> weight->i_denom) + weight->i_offset )
#define opscale_noden(x) dst[x] = x264_clip_uint8( src[x] * weight->i_scale + weight->i_offset )
static inline void mc_weight( uint8_t *dst, int i_dst_stride, uint8_t *src, int i_src_stride, const x264_weight_t *weight, int i_width, int i_height )
{
if( weight->i_denom >= 1 )
{
for( int y = 0; y < i_height; y++, dst += i_dst_stride, src += i_src_stride )
for( int x = 0; x < i_width; x++ )
opscale( x );
}
else
{
for( int y = 0; y < i_height; y++, dst += i_dst_stride, src += i_src_stride )
for( int x = 0; x < i_width; x++ )
opscale_noden( x );
}
}
如何验证 get_ref() 函数中对 pixel_avg() 函数和 mc_weight() 函数的调用被 inline 了呢?
一方面,可以通过 objdump 查看函数
get_ref()的反汇编来验证。% objdump -d ../625.x264_s | awk -v RS= '/^[[:xdigit:]]+ <get_ref>/'另一方面,可以通过查看编译 x264_src/common/mc.c 时生成 OptimizationRemark 来确认。
因为在编译 SPEC 2017 时为 cmake 添加了
-DCMAKE_EXPORT_COMPILE_COMMANDS=ON选项,所以可以在 llvm-test-suite-build/compile_commands.json 中找到编译 x264_src/common/mc.c 使用的命令:% $LLVM_BUILD_PATH/bin/clang \ -DNDEBUG -DSPEC -DSPEC_AUTO_BYTEORDER=0x12345678 -DSPEC_CPU -DSPEC_LINUX \ -DSPEC_LINUX_X64 -DSPEC_LP64 -DSPEC_SUPPRESS_OPENMP \ -I$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src \ -I$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/extras \ -I$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common \ -O3 -w -Werror=date-time -save-stats=obj -save-stats=obj \ -c $SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/mc.c为上述编译命令添加
-Rpass="inline|vectorize"选项,手动编译 x264_src/common/mc.c,通过查看 OptimizationRemark 可以看到get_ref()函数中对pixel_avg()函数和mc_weight()函数的调用确实被 inline 了。$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/mc.c:244:9: remark: ‘pixel_avg’ inlined into ‘get_ref’ with (cost=25, threshold=325) at callsite get_ref:12:9; [-Rpass=inline]
$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/mc.c:247:13: remark: ‘mc_weight’ inlined into ‘get_ref’ with (cost=190, threshold=325) at callsite get_ref:15:13; [-Rpass=inline]
$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/mc.c:252:9: remark: ‘mc_weight’ inlined into ‘get_ref’ with (cost=190, threshold=325) at callsite get_ref:20:9; [-Rpass=inline]
继续分析 Loop Vectorizer 对函数get_ref() 的向量化优化。
在编译 x264_src/common/mc.c 时生成 OptimizationRemark 中同样可以看到,Loop Vectorizer 将 inline 到函数 get_ref() 中的 pixel_avg() 函数和 mc_weight() 函数向量化了:
$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/mc.c:44:9: remark: vectorized loop (vectorization width: 16, interleaved count: 2) [-Rpass=loop-vectorize]
44 | for( int x = 0; x < i_width; x++ )
$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/mc.c:127:13: remark: vectorized loop (vectorization width: 4, interleaved count: 1) [-Rpass=loop-vectorize]
127 | for( int x = 0; x < i_width; x++ )
$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/mc.c:133:13: remark: vectorized loop (vectorization width: 4, interleaved count: 1) [-Rpass=loop-vectorize]
133 | for( int x = 0; x < i_width; x++ )
详细对比函数 get_ref() 在 Loop Vectorizer 前后 LLVM IR 的具体变化,可以在 x264_src/common/mc.c 的编译命令中分别添加 -mllvm -print-before=loop-vectorize 和 -mllvm -print-after=loop-vectorize 选项,手动编译两次 x264_src/common/mc.c。
我将函数 get_ref() 在 Loop Vectorizer 前后 LLVM IR 上传到了 github gist:
SLP Vectorizer
通过 perf 信息,可以看到开启 SLP Vectorizer 后 x264 的性能提升主要来自于对 x264_pixel_sad_16x16() 函数的优化。
函数 x264_pixel_sad_16x16() 的定义位于 x264_src/common/pixel.c 中,源代码如下:
/****************************************************************************
* pixel_sad_WxH
****************************************************************************/
#define PIXEL_SAD_C( name, lx, ly ) \
static int name( uint8_t *pix1, int i_stride_pix1, \
uint8_t *pix2, int i_stride_pix2 ) \
{ \
int i_sum = 0; \
for( int y = 0; y < ly; y++ ) \
{ \
for( int x = 0; x < lx; x++ ) \
{ \
i_sum += abs( pix1[x] - pix2[x] ); \
} \
pix1 += i_stride_pix1; \
pix2 += i_stride_pix2; \
} \
return i_sum; \
}
PIXEL_SAD_C( x264_pixel_sad_16x16, 16, 16 )
PIXEL_SAD_C( x264_pixel_sad_16x8, 16, 8 )
PIXEL_SAD_C( x264_pixel_sad_8x16, 8, 16 )
PIXEL_SAD_C( x264_pixel_sad_8x8, 8, 8 )
PIXEL_SAD_C( x264_pixel_sad_8x4, 8, 4 )
PIXEL_SAD_C( x264_pixel_sad_4x8, 4, 8 )
PIXEL_SAD_C( x264_pixel_sad_4x4, 4, 4 )
在 llvm-test-suite-build/compile_commands.json 中找到编译 x264_src/common/pixel.c 使用的命令:
% $LLVM_BUILD_PATH/bin/clang \
-DNDEBUG -DSPEC -DSPEC_AUTO_BYTEORDER=0x12345678 -DSPEC_CPU -DSPEC_LINUX \
-DSPEC_LINUX_X64 -DSPEC_LP64 -DSPEC_SUPPRESS_OPENMP \
-I$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src \
-I$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/extras \
-I$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common \
-O3 -w -Werror=date-time \
-c $SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/pixel.c
首先为上述编译命令添加 -Rpass="vectorize" 选项,手动编译 x264_src/common/pixel.c,通过查看 OptimizationRemark 可以看到 x264_src/common/pixel.c:61:1 即函数 x264_pixel_sad_16x16() 确实被 SLP Vectorizer 向量化了。
$SPEC_CPU2017_PATH/benchspec/CPU/525.x264_r/src/x264_src/common/pixel.c:61:1: remark: Vectorized horizontal reduction with cost -47 and with tree size 6 [-Rpass=slp-vectorizer]
61 | PIXEL_SAD_C( x264_pixel_sad_16x16, 16, 16 )
然后在上述编译命令中分别添加 -mllvm -print-before=slp-vectorizer 和 -mllvm -print-after=slp-vectorizer 选项,手动编译两次 x264_src/common/pixel.c,对比 SLP Vectorizer 前后 LLVM IR 的具体变化:
这里详细分析下 SLP Vectorizer 对函数 x264_pixel_sad_16x16() 的向量化优化:
在上一篇文章 SLP Vectorizer: Part 1 - Implementation in LLVM 中提到:SLP Vectorizer 会遍历每个函数的所有基本块,对于每个基本块,依次调用 vectorizeStoreChains(),vectorizeChainsInBlock(),vectorizeGEPIndices() 尝试向量化。对于函数 x264_pixel_sad_16x16(),是 vectorizeChainsInBlock() 找到了 horizontal reduction 的向量化机会,成功向量化。
horizontal reduction 如下图所示:
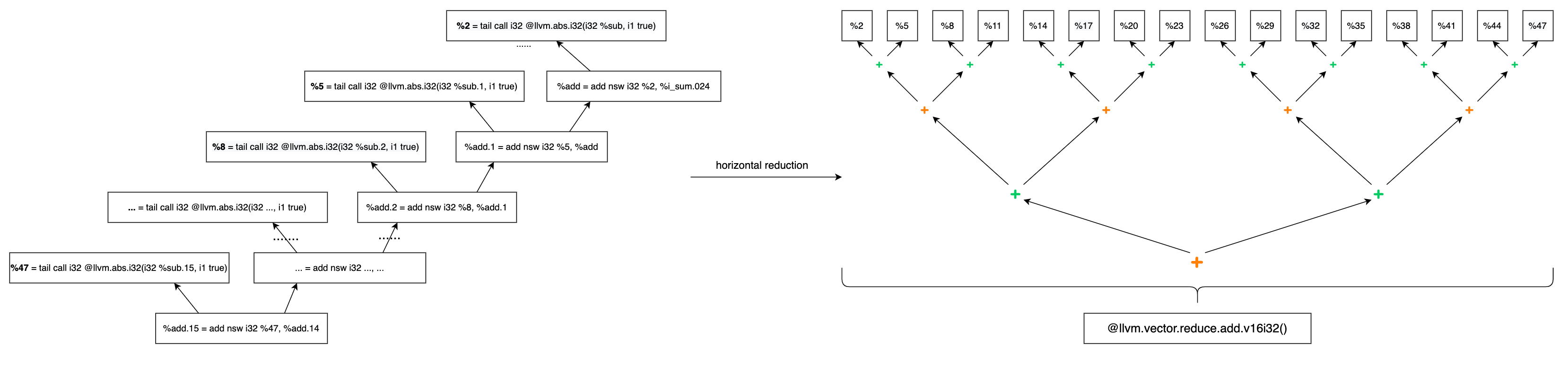
以 horizontal reduction 为根结点构建的 SLP Tree 如下图所示:
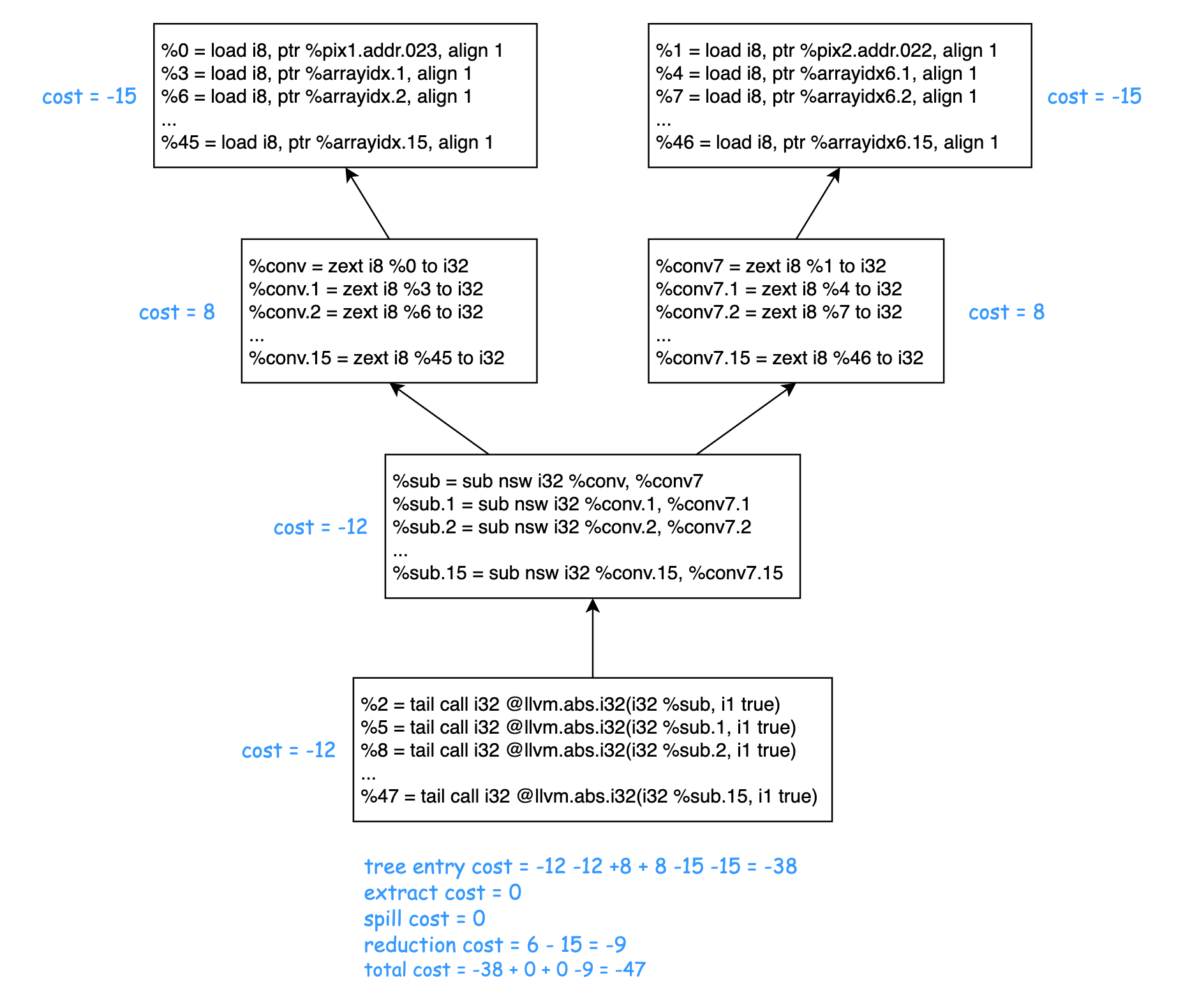
函数
x264_pixel_sad_16x16()经 SLP Vectorizer 向量化后的 LLVM IR 非常简洁:; *** IR Dump After SLPVectorizerPass on x264_pixel_sad_16x16 *** ; Function Attrs: nofree norecurse nosync nounwind memory(read, inaccessiblemem: none) uwtable define internal i32 @x264_pixel_sad_16x16( ptr nocapture noundef readonly %pix1, i32 noundef %i_stride_pix1, ptr nocapture noundef readonly %pix2, i32 noundef %i_stride_pix2) { entry: %idx.ext = sext i32 %i_stride_pix1 to i64 %idx.ext8 = sext i32 %i_stride_pix2 to i64 br label %for.cond1.preheader for.cond1.preheader: ; preds = %entry, %for.cond1.preheader %y.025 = phi i32 [ 0, %entry ], [ %inc11, %for.cond1.preheader ] %i_sum.024 = phi i32 [ 0, %entry ], [ %op.rdx, %for.cond1.preheader ] %pix1.addr.023 = phi ptr [ %pix1, %entry ], [ %add.ptr, %for.cond1.preheader ] %pix2.addr.022 = phi ptr [ %pix2, %entry ], [ %add.ptr9, %for.cond1.preheader ] %0 = load <16 x i8>, ptr %pix1.addr.023, align 1, !tbaa !14 %1 = zext <16 x i8> %0 to <16 x i32> %2 = load <16 x i8>, ptr %pix2.addr.022, align 1, !tbaa !14 %3 = zext <16 x i8> %2 to <16 x i32> %4 = sub nsw <16 x i32> %1, %3 %5 = call <16 x i32> @llvm.abs.v16i32(<16 x i32> %4, i1 true) %6 = call i32 @llvm.vector.reduce.add.v16i32(<16 x i32> %5) %op.rdx = add i32 %6, %i_sum.024 %add.ptr = getelementptr inbounds i8, ptr %pix1.addr.023, i64 %idx.ext %add.ptr9 = getelementptr inbounds i8, ptr %pix2.addr.022, i64 %idx.ext8 %inc11 = add nuw nsw i32 %y.025, 1 %exitcond.not = icmp eq i32 %inc11, 16 br i1 %exitcond.not, label %for.cond.cleanup, label %for.cond1.preheader, !llvm.loop !30 for.cond.cleanup: ; preds = %for.cond1.preheader ret i32 %op.rdx }
Summary
在上一篇文章 SLP Vectorizer: Part 1 - Implementation in LLVM 中我们学习 LLVM 的 SLP Vectorizer 实现,本文基于 SPEC CPU 2017 来评估 SLP Vectorizer 的优化效果。
在 SPEC CPU 2017 上测试, SLP Vectorizer 在 x264 上带来的性能提升远大于 Loop Vectorizer
在 x264 上,主要是 SLP Vectorizer 的
vectorizeChainsInBlock()找到了 horizontal reduction 的向量化机会带来的性能提升
P.S.
如果不开启 Loop Vectorizer 只开启 SLP Vectorizer,SLP Vectorizer 在 x264 上能带来多大的性能提升呢?不开启 Loop Vectorizer 只开启 SLP Vectorizer 运行 SPEC 2017 的结果如下:
只开启 Loop Vectorizer,将 x264 运行时间从 44.94s(44.70s) 优化到 38.31s(38.35s),优化了 6.64s(6.35s),有相对 14.8%(14.2%) 的收益。
只开启 SLP Vectorizer,将 x264 运行时间从 44.94s(44.70s) 优化到 31.28s(31.31s),优化了 13.67s(13.39s),有相对 30.4%(30.0%) 的收益。因此,在 x264 上只开启 SLP Vectorizer 带来的性能提升也是大于只开启 Loop Vectorizer 带来的性能提升的。
Program exec_time O3-no-LV.results test-suite :: External/SPEC/CINT2017speed/625.x264_s/625.x264_s.test 31.31 test-suite :: External/SPEC/CINT2017rate/525.x264_r/525.x264_r.test 31.28 test-suite :: External/SPEC/CFP2017speed/619.lbm_s/619.lbm_s.test 18.55 test-suite :: External/SPEC/CINT2017speed/631.deepsjeng_s/631.deepsjeng_s.test 12.18 test-suite :: External/SPEC/CINT2017rate/557.xz_r/557.xz_r.test 11.21 test-suite :: External/SPEC/CINT2017speed/657.xz_s/657.xz_s.test 11.17 test-suite :: External/SPEC/CINT2017rate/500.perlbench_r/500.perlbench_r.test 10.53 test-suite :: External/SPEC/CINT2017speed/600.perlbench_s/600.perlbench_s.test 10.51 test-suite :: External/SPEC/CINT2017speed/605.mcf_s/605.mcf_s.test 9.85 test-suite :: External/SPEC/CINT2017rate/505.mcf_r/505.mcf_r.test 9.84 test-suite :: External/SPEC/CINT2017rate/531.deepsjeng_r/531.deepsjeng_r.test 7.22 test-suite :: External/SPEC/CINT2017speed/641.leela_s/641.leela_s.test 5.26 test-suite :: External/SPEC/CINT2017rate/541.leela_r/541.leela_r.test 5.26 test-suite :: External/SPEC/CFP2017rate/510.parest_r/510.parest_r.test 5.16 test-suite :: External/SPEC/CFP2017rate/508.namd_r/508.namd_r.test 4.36 test-suite :: External/SPEC/CINT2017rate/520.omnetpp_r/520.omnetpp_r.test 2.63 test-suite :: External/SPEC/CINT2017speed/620.omnetpp_s/620.omnetpp_s.test 2.63 test-suite :: External/SPEC/CFP2017rate/519.lbm_r/519.lbm_r.test 2.29 test-suite :: External/SPEC/CFP2017rate/544.nab_r/544.nab_r.test 2.01 test-suite :: External/SPEC/CFP2017speed/644.nab_s/644.nab_s.test 1.98 test-suite :: External/SPEC/CFP2017rate/511.povray_r/511.povray_r.test 0.33 test-suite :: External/SPEC/CFP2017rate/526.blender_r/526.blender_r.test 0.17 test-suite :: External/SPEC/CINT2017rate/523.xalancbmk_r/523.xalancbmk_r.test 0.06 test-suite :: External/SPEC/CINT2017speed/623.xalancbmk_s/623.xalancbmk_s.test 0.06 test-suite :: External/SPEC/CFP2017speed/638.imagick_s/638.imagick_s.test 0.01 test-suite :: External/SPEC/CFP2017rate/538.imagick_r/538.imagick_r.test 0.01 test-suite :: External/SPEC/CFP2017rate/997.specrand_fr/997.specrand_fr.test 0.01 test-suite :: External/SPEC/CINT2017rate/999.specrand_ir/999.specrand_ir.test 0.01 test-suite :: External/SPEC/CINT2017speed/998.specrand_is/998.specrand_is.test 0.01 test-suite :: External/SPEC/CFP2017speed/996.specrand_fs/996.specrand_fs.test 0.01 test-suite :: External/SPEC/CINT2017rate/502.gcc_r/502.gcc_r.test 0.01 test-suite :: External/SPEC/CINT2017speed/602.gcc_s/602.gcc_s.test 0.01查看 x264 在 O3 优化等级下函数
x264_pixel_sad_16x16的反汇编:% objdump -d 625.x264_s | awk -v RS= '/^[[:xdigit:]]+ <x264_pixel_sad_16x16>/' 000000000000f2e0 <x264_pixel_sad_16x16>: f2e0: 48 63 f6 movslq %esi,%rsi f2e3: 48 63 c9 movslq %ecx,%rcx f2e6: 31 c0 xor %eax,%eax f2e8: 41 b8 10 00 00 00 mov $0x10,%r8d f2ee: 66 90 xchg %ax,%ax f2f0: f3 0f 6f 07 movdqu (%rdi),%xmm0 f2f4: f3 0f 6f 0a movdqu (%rdx),%xmm1 f2f8: 66 0f f6 c8 psadbw %xmm0,%xmm1 f2fc: 66 0f 70 c1 ee pshufd $0xee,%xmm1,%xmm0 f301: 66 0f d4 c1 paddq %xmm1,%xmm0 f305: 66 41 0f 7e c1 movd %xmm0,%r9d f30a: 44 01 c8 add %r9d,%eax f30d: 48 01 f7 add %rsi,%rdi f310: 48 01 ca add %rcx,%rdx f313: 41 ff c8 dec %r8d f316: 75 d8 jne f2f0 <x264_pixel_sad_16x16+0x10> f318: c3 retq f319: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)LLVM 为函数
x264_pixel_sad_16x16由 LLVM IR 生成汇编时也做了一定的“优化”,生成了 psadbw 指令,PSADBW — Compute Sum of Absolute Differences:TEMP0 := ABS(DEST[7:0] - SRC[7:0]) (* Repeat operation for bytes 2 through 14 *) TEMP15 := ABS(DEST[127:120] - SRC[127:120]) DEST[15:0] := SUM(TEMP0:TEMP7) DEST[63:16] := 000000000000H DEST[79:64] := SUM(TEMP8:TEMP15) DEST[127:80] := 00000000000 DEST[MAXVL-1:128] (Unmodified)-O3v.s.-O3 -march=native -mtune=native开启
-march=native -mtune=native选项会多暴露一些优化机会,可以通过clang -E - -march=native -mtune=native -###查看具体 pass 了哪些-target-cpu,-tune-cpu,-target-feature给 cc1。开启
-march=native -mtune=native选项并不影响本文的结论,具体的开启-march=native -mtune=native选项后运行 SPEC 2017 的结果如下:-O3 -march=native -mtune=native -fno-vectorize -fno-slp-vectorizeProgram exec_time O3-no-LV-SLP.results INT2017rate/525.x264_r/525.x264_r 43.80 INT2017speed/625.x264_s/625.x264_s 43.72 FP2017speed/619.lbm_s/619.lbm_s 16.94 INT2017spe...31.deepsjeng_s/631.deepsjeng_s 11.86 INT2017speed/657.xz_s/657.xz_s 11.03 INT2017rate/557.xz_r/557.xz_r 10.98 INT2017spe...00.perlbench_s/600.perlbench_s 10.85 INT2017rat...00.perlbench_r/500.perlbench_r 10.83 INT2017rate/505.mcf_r/505.mcf_r 9.79 INT2017speed/605.mcf_s/605.mcf_s 9.73 INT2017rat...31.deepsjeng_r/531.deepsjeng_r 6.92 INT2017speed/641.leela_s/641.leela_s 5.31 INT2017rate/541.leela_r/541.leela_r 5.31 FP2017rate/510.parest_r/510.parest_r 5.08 FP2017rate/508.namd_r/508.namd_r 3.99 INT2017rate/520.omnetpp_r/520.omnetpp_r 2.67 INT2017spe...ed/620.omnetpp_s/620.omnetpp_s 2.63 FP2017rate/519.lbm_r/519.lbm_r 2.02 FP2017speed/644.nab_s/644.nab_s 1.43 FP2017rate/544.nab_r/544.nab_r 1.40 FP2017rate/511.povray_r/511.povray_r 0.30 FP2017rate/526.blender_r/526.blender_r 0.16 INT2017rat...23.xalancbmk_r/523.xalancbmk_r 0.06 INT2017spe...23.xalancbmk_s/623.xalancbmk_s 0.06 FP2017rate/538.imagick_r/538.imagick_r 0.01 FP2017speed/638.imagick_s/638.imagick_s 0.01 INT2017rate/502.gcc_r/502.gcc_r 0.01 INT2017spe...98.specrand_is/998.specrand_is 0.01 FP2017spee...96.specrand_fs/996.specrand_fs 0.01 INT2017rat...99.specrand_ir/999.specrand_ir 0.01 FP2017rate...97.specrand_fr/997.specrand_fr 0.01 INT2017speed/602.gcc_s/602.gcc_s 0.01-O3 -march=native -mtune=native -fno-slp-vectorizeProgram exec_time O3-no-SLP.results INT2017rate/525.x264_r/525.x264_r 38.76 INT2017speed/625.x264_s/625.x264_s 38.76 FP2017speed/619.lbm_s/619.lbm_s 17.10 INT2017spe...31.deepsjeng_s/631.deepsjeng_s 11.77 INT2017speed/657.xz_s/657.xz_s 11.16 INT2017rate/557.xz_r/557.xz_r 11.15 INT2017speed/605.mcf_s/605.mcf_s 10.55 INT2017spe...00.perlbench_s/600.perlbench_s 10.55 INT2017rate/505.mcf_r/505.mcf_r 10.54 INT2017rat...00.perlbench_r/500.perlbench_r 10.53 INT2017rat...31.deepsjeng_r/531.deepsjeng_r 6.88 FP2017rate/510.parest_r/510.parest_r 5.42 INT2017rate/541.leela_r/541.leela_r 5.30 INT2017speed/641.leela_s/641.leela_s 5.29 FP2017rate/508.namd_r/508.namd_r 4.18 INT2017spe...ed/620.omnetpp_s/620.omnetpp_s 2.64 INT2017rate/520.omnetpp_r/520.omnetpp_r 2.60 FP2017rate/519.lbm_r/519.lbm_r 2.02 FP2017speed/644.nab_s/644.nab_s 1.50 FP2017rate/544.nab_r/544.nab_r 1.47 FP2017rate/511.povray_r/511.povray_r 0.31 FP2017rate/526.blender_r/526.blender_r 0.16 INT2017spe...23.xalancbmk_s/623.xalancbmk_s 0.06 INT2017rat...23.xalancbmk_r/523.xalancbmk_r 0.06 FP2017speed/638.imagick_s/638.imagick_s 0.01 FP2017rate/538.imagick_r/538.imagick_r 0.01 INT2017rate/502.gcc_r/502.gcc_r 0.01 INT2017rat...99.specrand_ir/999.specrand_ir 0.01 FP2017spee...96.specrand_fs/996.specrand_fs 0.01 FP2017rate...97.specrand_fr/997.specrand_fr 0.01 INT2017spe...98.specrand_is/998.specrand_is 0.01 INT2017speed/602.gcc_s/602.gcc_s 0.01-O3 -march=native -mtune=nativeProgram exec_time O3.results INT2017rate/525.x264_r/525.x264_r 21.40 INT2017speed/625.x264_s/625.x264_s 21.35 FP2017speed/619.lbm_s/619.lbm_s 17.16 INT2017spe...31.deepsjeng_s/631.deepsjeng_s 11.81 INT2017speed/657.xz_s/657.xz_s 11.20 INT2017rate/557.xz_r/557.xz_r 11.19 INT2017spe...00.perlbench_s/600.perlbench_s 10.86 INT2017rat...00.perlbench_r/500.perlbench_r 10.83 INT2017speed/605.mcf_s/605.mcf_s 10.68 INT2017rate/505.mcf_r/505.mcf_r 10.65 INT2017rat...31.deepsjeng_r/531.deepsjeng_r 6.85 FP2017rate/510.parest_r/510.parest_r 5.47 INT2017rate/541.leela_r/541.leela_r 5.26 INT2017speed/641.leela_s/641.leela_s 5.26 FP2017rate/508.namd_r/508.namd_r 4.18 INT2017spe...ed/620.omnetpp_s/620.omnetpp_s 2.62 INT2017rate/520.omnetpp_r/520.omnetpp_r 2.61 FP2017rate/519.lbm_r/519.lbm_r 2.00 FP2017rate/544.nab_r/544.nab_r 1.39 FP2017speed/644.nab_s/644.nab_s 1.39 FP2017rate/511.povray_r/511.povray_r 0.31 FP2017rate/526.blender_r/526.blender_r 0.16 INT2017spe...23.xalancbmk_s/623.xalancbmk_s 0.06 INT2017rat...23.xalancbmk_r/523.xalancbmk_r 0.06 FP2017speed/638.imagick_s/638.imagick_s 0.01 FP2017rate/538.imagick_r/538.imagick_r 0.01 INT2017rate/502.gcc_r/502.gcc_r 0.01 INT2017rat...99.specrand_ir/999.specrand_ir 0.01 FP2017spee...96.specrand_fs/996.specrand_fs 0.01 INT2017spe...98.specrand_is/998.specrand_is 0.01 FP2017rate...97.specrand_fr/997.specrand_fr 0.01 INT2017speed/602.gcc_s/602.gcc_s 0.01